You are viewing the RapidMiner Radoop documentation for version 7.6 - Check here for latest version
What’s New in RapidMiner Radoop 7.1?
This page describes the new features of RapidMiner Radoop 7.1 as well as its enhancements and bug fixes.
Update / migration
Please note that RapidMiner Radoop 7.1 is not backwards compatible and requires RapidMiner Studio 7.1 and/or RapidMiner Server 7.1. Update is available through the RapidMiner Marketplace.
Distribution support
RapidMiner Radoop 7.1 continues to work with the latest Cloudera and Hortonworks distributions, and adds support for Open Data Platform and IBM BigInsights distributions.
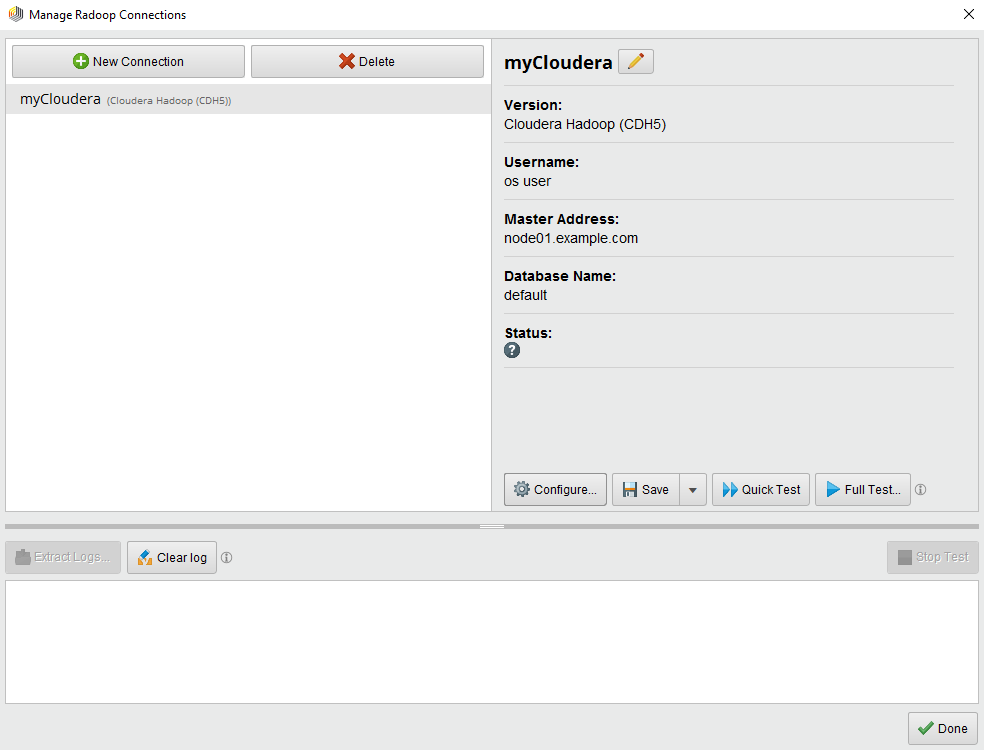
New connection dialog and connection wizard
RapidMiner Radoop 7.1 delivers a completely redesigned connection dialog and a connection wizard to ease initial integration efforts.
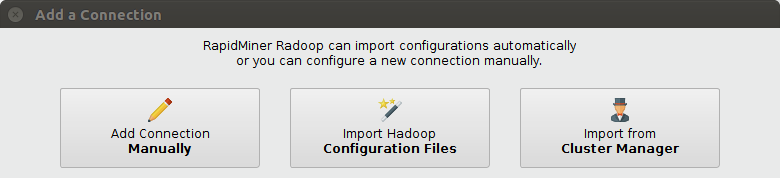
Hadoop configuration files can be easily imported to pre-fill most of the connection details so it reduces the need for tedious and error-prone configuration steps.
Improved error reporting
Hadoop is a complex system and there are so many things that can go wrong. Permission errors, wrong version of libraries, malformed data, out of memory errors, and the list could go on. Many of those errors are hidden in the thousands of log files of Hadoop, hence it is hard to figure out where to look during troubleshooting. RapidMiner Radoop 7.1 includes a lot of smart heuristics to extract the actual cause of many potential errors and guide you in solving those problems.
Enhancements and bug fixes
The following improvements are part of RapidMiner Radoop 7.1.
Enhancements
- Redesigned Manage Radoop Connections dialog entirely
- Added support for password based Kerberos authentication (instead of using keytab files)
- Added new option to create Radoop connection automatically from Hadoop configuration files
- Added explicit support for Open Data Platform (new Hadoop Version on Radoop Connection dialog)
- Added explicit support for IBM Open Platform (new Hadoop Version on Radoop Connection dialog)
- Introduced progress display for Radoop operators that precisely shows what is running
- Added special log message for Spark Script if R is missing on the cluster
- Added Export Logs... option to the Radoop Connection Dialog to gather and compress all logs to help support
- Added Preference setting to enable log4j logging
- Introduced grouping in Radoop Preference settings
- Introduced highlighting for missing or incorrect fields on the Advanced Connection Properties dialog
- Added tooltip icons to the Advanced Connection Properties dialog
- Hive-on-Tez is now supported on recent distribution releases, if the cluster-side configuration sets it (config no longer overridden)
- Operation / query logs are now retrieved to the Log panel from Hive if possible; related error messages are improved
- Global configuration parameters can be set and passed to the suprocess of the Single Process Pushdown operator
- Added support for macros to Single Process Pushdown operator
- Single Process Pushdown job now reports if it runs out of memory and stops as soon as possible
- HDFS import (Read CSV or import from Hadoop Data view) now reports parsing errors on the Log panel
- Clustering algorithms now report job errors on the Log panel
- The Hadoop property mapreduce.application.classpath is no longer modified to include configuration as a workaround
- The key for decrypting sensitive fields can now be specified on a per-entry basis in radoop_connections.xml (useful on Server)
- Two Sentry related advanced Hadoop parameters no longer need to be specified for secure Impala connection
- Added explicit error messages during process execution for operators not supported on Impala
- Added warning for space in keytab path (that may not work)
Bug fixes
- BUGFIX: Decision Tree and Random Forest no longer fail to convert some categorical splits in the model
- BUGFIX: Create Permanent UDFs test and function creation now reports errors correctly
- BUGFIX: Clean Temporary Data action no longer throws error and stops when another tree item is selected
- BUGFIX: Store no longer ignores serde properties settings when a custom storage handler is specified
- BUGFIX: Spark Script error log collection no longer fails for some container IDs
- BUGFIX: Auxiliary jar files (radoop_hive, radoop, radoop_spark) are no longer uploaded multiple times
- BUGFIX: Mahout test and clustering operators with missing values no longer fail on Hadoop v1
- BUGFIX: Create Permanent UDFs test no longer warns about rapidminer_libs jar version difference incorrectly
- BUGFIX: Connection entry with Other Hadoop version and invalid Additional Libraries Directory no longer breaks Hadoop Data view
- BUGFIX: Impala now correctly reads the integer columns on the output of Single Process Pushdown
- BUGFIX: The Hive Decimal type is now converted to real instead of integer
- BUGFIX: Mahout test and other operations no longer fail on older Hive versions because of wrong default field separator settings