You are viewing the RapidMiner Radoop documentation for version 9.0 - Check here for latest version
Configuring RapidMiner Radoop with Hadoop Security
Often, organizations implement Hadoop security on their clusters to protect against unauthorized data access and other security breaches. Although Kerberos is widely used across distributions for authentication, there are a variety of other authorization and data encryption technologies available. For more information, read RapidMiner's Big Data Security on Hadoop OrangePaper.
RapidMiner Radoop currently supports Kerberos authentication, data authorization with Apache Sentry, with Apache Ranger and via SQL standards with Apache Hive.
If your Hadoop cluster is “kerberized”, third-party tools can only access it via Kerberos authentication. In RapidMiner Radoop, provide the necessary Kerberos settings in the Connection Settings window.
The secure configuration requires a personal keytab file or Kerberos password. You (or your security administrator) can generate the keytab file using the kadmin tool. If you use 256-bit AES encryption for the keytab, you must install the Java Cryptography Extension. Authenticating with the Kerberos user/pass is supported and it does not require further configuration.
-
Select the Enable security checkbox in the Security Settings panel. Several new parameters appear.
-
Provide values for the following parameters (bold names on the panel indicate required fields):
| Field | Description |
|---|---|
| Keytab File | Path of the user keytab file on the client machine. Enter or browse to the file location. |
| Use password instead of keytab file | Check this box if you want to authenticate with a Kerberos password. The Password fields becomes enabled and the Keytab File field disabled if this is checked. |
| Password | The Kerberos password for the Client Principal. This value is encrypted in the radoop-connections.xml file. |
| Client Principal | Principal of the user accessing Hadoop. The format is primary[/<instance>]@<REALM>, where primary is usually the user name, instance is optional, and REALM is the Kerberos realm. Example: user/client.rapidminer.com@RAPIDMINER.COM). |
| REALM | The Kerberos realm. It is usually the domain name in upper-case letters. Example: RAPIDMINER.COM. |
| KDC Address | Address of the Kerberos Key Distribution Center. Example: kdc.rapidminer.com. |
| Kerberos Config File | To avoid configuration differences between the machine running RapidMiner and the Hadoop cluster, it is good practice to provide the Kerberos configuration file (usually krb5.conf or krb5.ini). Obtain this file from your security administrator. Enter or browse to the file location. |
| Hive Principal | Principal of the Hive service. The format is primary[/<instance>]@<REALM>, where primary is usually the service/user name, instance is the host name, and REALM is the Kerberos realm. Do not use the _HOST keyword as the instance. If Hive is not configured for Kerberos but uses another authentication mechanism (e.g., LDAP), leave this field empty. Example: hive/node02.rapidminer.com@RAPIDMINER.COM. |
| SASL QoP Level | Level of SASL Quality of Protection. This setting must be the same as the cluster setting. (To find the cluster setting, find the value of hive.server2.thrift.sasl.qop in hive-site.xml; the default is “auth”.) |
| Retrieve Principals from Hive | If checked, RapidMiner Radoop automatically retrieves all other service principals from Hive for easier configuration. Disable this setting only if there is a problem accessing other services. If disabled, you must provide the principals of the following services — NameNode Principal, Resource Manager Principal, Job History Server Principal — sing the format <primary>/<instance>]@<REALM>. (Example: nn/_HOST@RAPIDMINER.COM, rm/_HOST@RAPIDMINER.COM, jhs/_HOST@RAPIDMINER.COM, respectively). You can use the _HOST keyword as the instance. |
To configure the Hadoop connection for RapidMiner Server, follow the RapidMiner Radoop installation guide for Server.
- If using keytab files for authentication and the Keytab File and Kerberos Config File reside on a different path for RapidMiner Server, update the fields in radoop_connections.xml.
- When using Kerberos password you may need to manually edit the radoop_connections.xml file on the Server in a multi-user environment.
Note: Kerberos authentication can also be enabled for Impala connections. In this case, provide the Impala Principal instead of the Hive Principal. Automatic retrieval of other service principals is not supported when using Impala, so these principals must be also provided on the interface.
Note: Long-running Spark processes may fail to relogin if using Kerberos password for authentication, as Spark supports this feature only with keytab files. Using larger Kerberos ticket expiration time may be a workaround for this issue.
Concurrent requests
When using RapidMiner Radoop on RapidMiner Studio, it cannot communicate concurrently with clusters that have different security settings. For example, when a process is running on a secure Hadoop cluster, you cannot use the Hadoop Data view to investigate data from another cluster. When using RapidMiner Radoop on RapidMiner Server, all concurrently running processes must use the same security settings. To avoid any potential concurrency issues, we recommend using a separate RapidMiner Server for each secure Hadoop cluster. Further information on concurrent requests to secure clusters with RapidMiner Server can be found on the Installing Radoop on Server page.
RapidMiner Radoop supports LDAP authentication to Hive, while the other services may be accessible using Kerberos authentication. To configure LDAP authentication to Hive please follow these steps:
- Leave the Hive Principal field empty to let Hadoop set the LDAP credentials.
- Set the Hive Username and Password fields with the user crendentials.
Apache Sentry provides fine-grained, role-based authorization to data stored on a Hadoop cluster. It is a common authorization tool for Cloudera clusters (and other distributions). The following steps configure Apache Sentry so that the full functionality of RapidMiner Radoop becomes available.
Create RapidMiner Radoop roles
To enable all RapidMiner Radoop functionality, create one or more roles in Sentry that can be applied to all users. Because Sentry roles can only be granted to groups, best practice suggests that all RapidMiner Radoop users belong to the same group(s).
Execute the following statements to create the roles and assign them to the RapidMiner user groups. For the remainder of this section, we will assume that the radoop_user_role is assigned to a single RapidMiner user and other users have their own roles.
CREATE ROLE radoop_user_role;
GRANT ROLE radoop_user_role TO GROUP group1;
Enable RapidMiner Radoop temporary tables
RapidMiner Radoop is not just a simple BI tool that uses Hive as a data source, it is also an advanced analytics tool that uses Hadoop as an execution environment. RapidMiner Radoop pushes jobs and queries down to the cluster for execution in Hadoop. To support complex analytics workflows, RapidMiner Radoop must be able to create new tables and store temporary results in Hive.
When using Sentry, you need all privileges to the database to be able to create new tables. In case of a shared database with fine-grained security settings, granting all rights may not be viable. In those cases, create a sandbox database for RapidMiner Radoop users and add the necessary input tables as views to the sandbox database.
Execute the following statements to create the database:
CREATE DATABASE radoop_user_sandbox;
GRANT ALL ON DATABASE radoop_user_sandbox TO ROLE radoop_user_role;
Execute the following statement for each input table that is added from other databases:
CREATE VIEW radoop_user_sandbox.view1 AS SELECT * FROM other_database.table1;
Enable RapidMiner Radoop data import
RapidMiner has connectors to many different data sources (databases, noSQL data stores, cloud services, multiple file formats, etc.) and can import those data sets into Hive. During the import, and during any other internal data materialization steps, RapidMiner Radoop is using the /tmp/radoop/<username> HDFS folder. (You can change this path in Settings.) Best practice suggests that security administrators create these user directories, ensuring that only <username> and the Hive user have all rights on it. All other users should be denied access this directory.
To enable a folder for data imports, execute the following statements:
GRANT ALL ON URI "hdfs:///tmp/radoop/<username>/" TO ROLE radoop_user_role;
GRANT ALL ON URI "hdfs://<fs.defaultFS>/tmp/radoop/<username>/" TO ROLE radoop_user_role;
Replace <fs.defaultFS> by the nameservice name or the <namenode:port address>, and replace <username> by the username on the Hadoop cluster.
If you have changed the default RapidMiner Radoop temporary directory (/tmp/radoop/), change the above statements accordingly.
Enable RapidMiner Radoop UDFs
Rapidminer Radoop uses custom UDF execution in Hive queries. With Sentry disabled, JAR files are uploaded to the HDFS and the UDFs are constructed based on those JARs. When enabled, Sentry disables the ability to define and execute UDFs from JARs uploaded to the HDFS. In that case, you must add the JARs to the local filesystem of the HiveServer2 and also add them to the Hive classpath.
To support UDFs in Rapidminer Radoop with Sentry enabled follow the instructions of the Installing RapidMiner Radoop functions manually section on the Operation and Maintenance page.
See the Cloudera documentation for more detailed description of UDFs and Sentry settings.
The following setup enables RapidMiner Radoop to work with Apache Ranger. This authorization is used with Hive 0.13 and above, and is a typical setup with the Hortonworks distribution.
Enable RapidMiner Radoop temporary tables
When using Ranger, you need all rights to the database to be able to create new tables. In case of a shared database with fine-grained security settings, granting all rights may not be viable. In those cases, create a sandbox database for RapidMiner Radoop users and add the necessary input tables as views to the sandbox database.
Execute the following statements to create the database:
CREATE DATABASE radoop_user_sandbox;
Create a Ranger Hive Policy, that allows all operations on all of the tables of this database for the user.
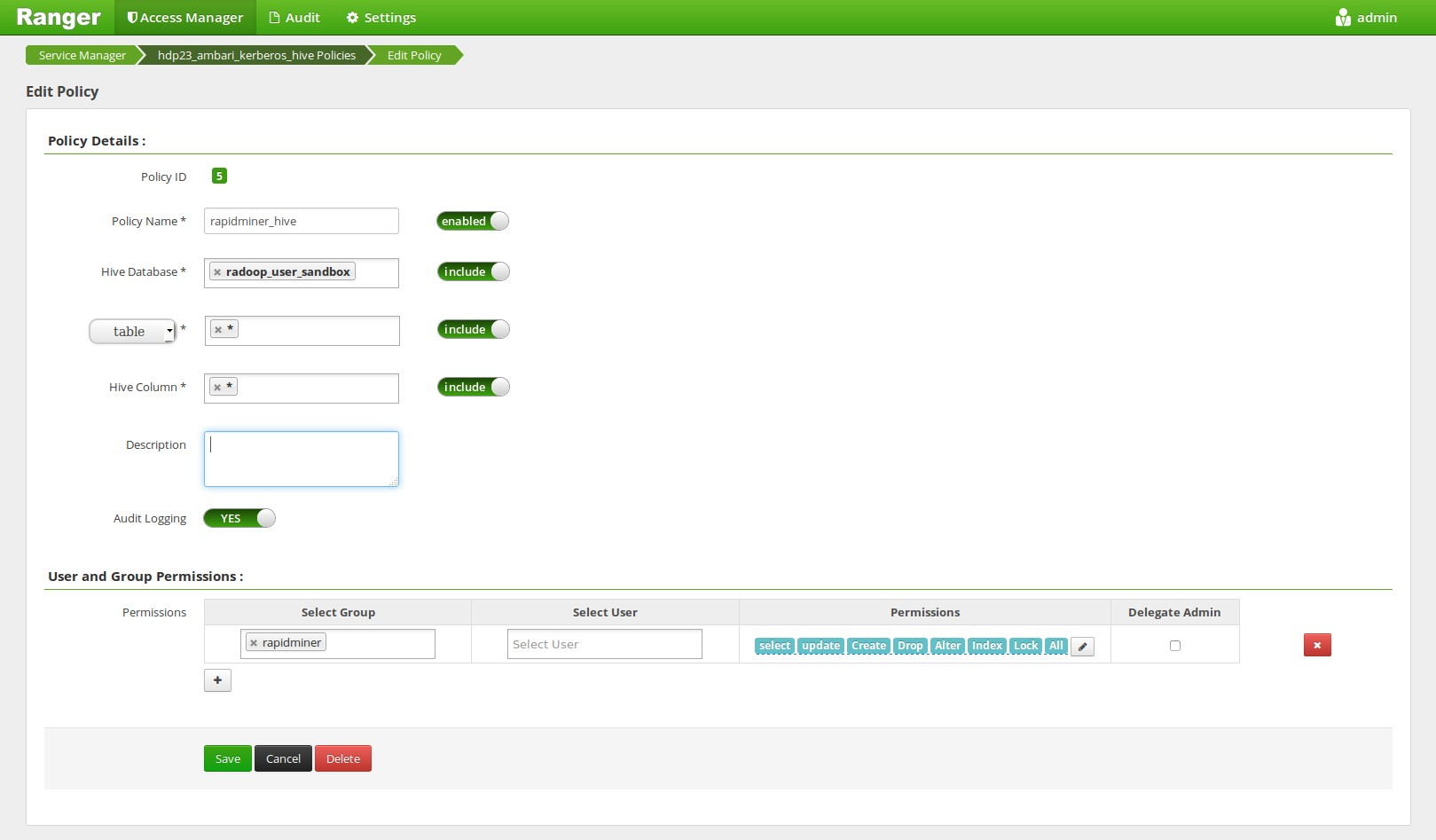
Execute the following statement for each input table that is added from other databases:
CREATE VIEW radoop_user_sandbox.view1 AS SELECT * FROM other_database.table1;
Enable RapidMiner Radoop UDFs
Rapidminer Radoop uses custom UDF execution in Hive queries. Without using Ranger, JAR files are uploaded to the HDFS and the UDFs are constructed based on those JARs. It’s possible to keep this behaviour with Ranger by creating a Ranger Hive Policy, that allows the execution of all UDFs of this database for the user. In this case the UDFs are upgraded automatically when you upgrade to a new RapidMiner Radoop version. If the policy cannot be set for any reason, please see the Installing RapidMiner Radoop functions manually section to install the UDFs on the cluster manually.
Setting the UDF policies on the Ambari Web UI (not required when doing manual function installation):
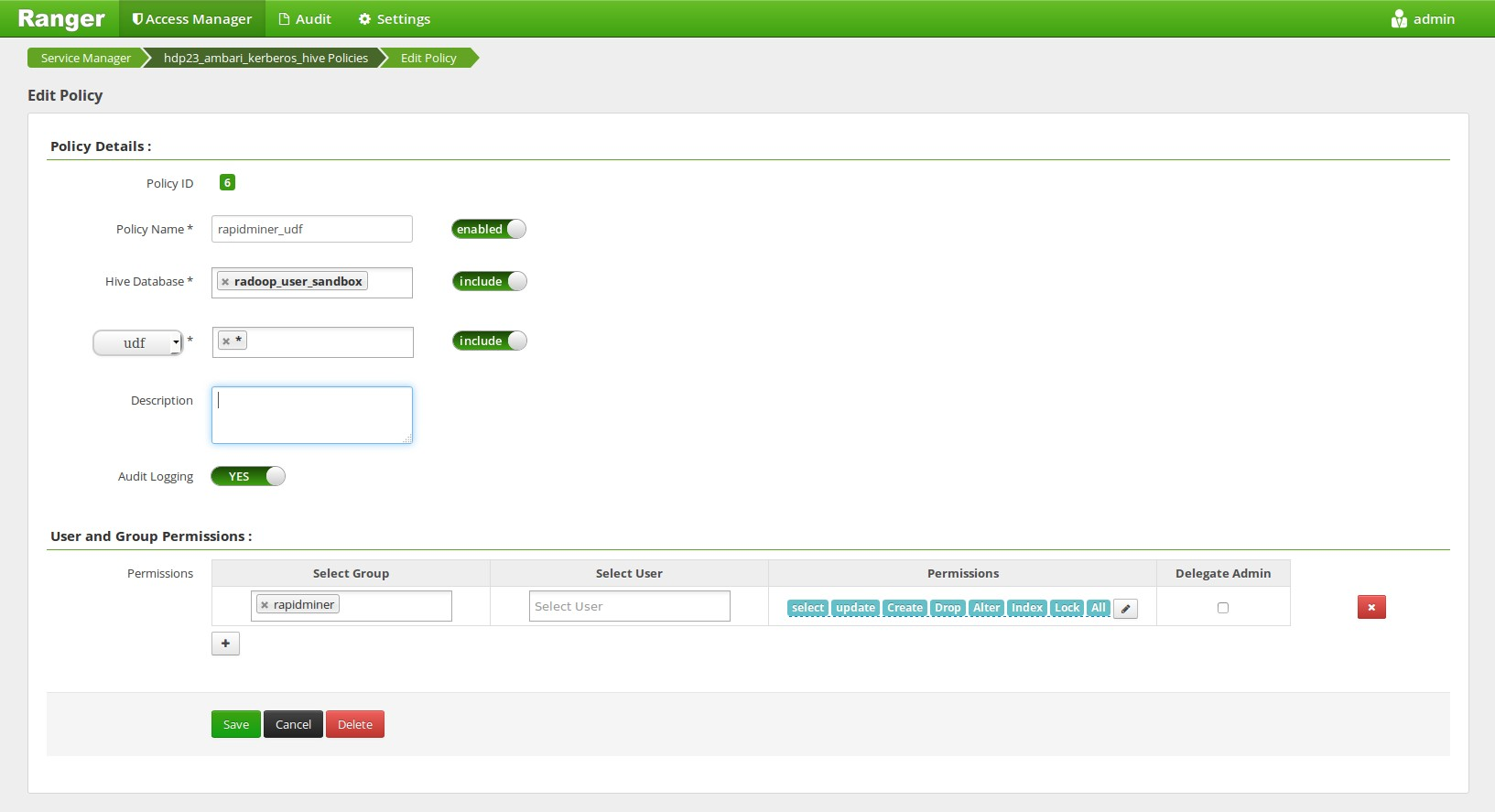
Accessing other HDFS directories
Create a Ranger HDFS Policy, that allows any HDFS operation within the users home directory (in our case the rapidminer user). If you are using SPARK and the Spark Assembly is located on the HDFS (e.g. in the /user/spark folder) then this user needs to have access to this folder also.
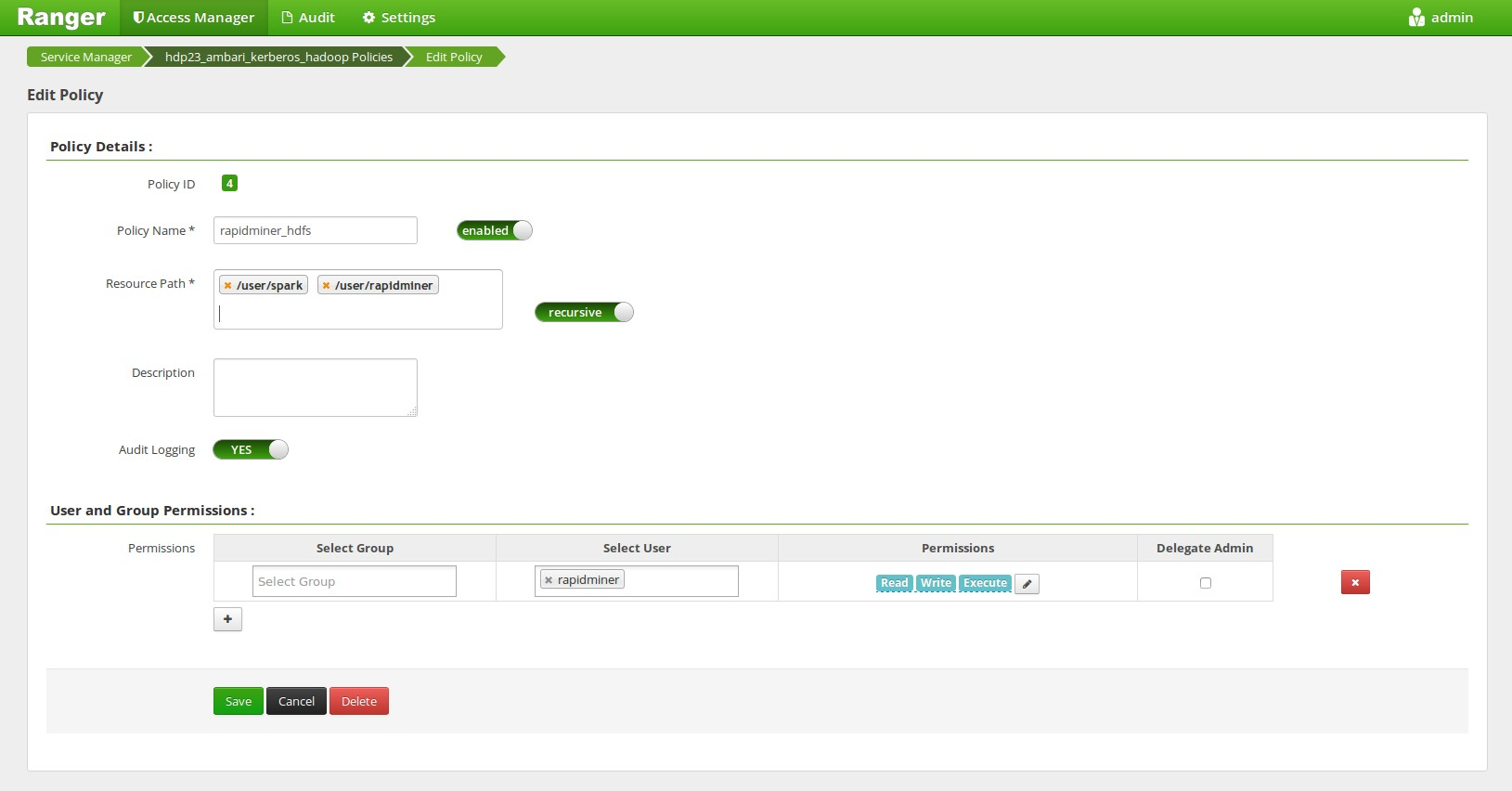
Please also note that RapidMiner Radoop must be able to create an HDFS directory to store its temporary files. The default path for that is /tmp/radoop. This path can be changed by changing the following property: rapidminer.radoop.hdfs_directory.
Create/Drop functions
Rapidminer Radoop uses custom UDFs in Hive queries. Creating these functions requires that the user is included in the admin policy, otherwise the permanent functions must be created manually by an admin. Further information on creating these functions can be found in the Installing RapidMiner Radoop functions manually section on the Operation and Maintenance page.
The following setup enables RapidMiner Radoop to work with SQL Standard Based Hive Authorization. This authorization is used with Hive 0.13 and above, and is a typical setup with the Hortonworks distribution.
Restrictions on Hive commands and statements
To fully operate on the cluster, RapidMiner Radoop requires the privilege to modify some properties through the HiveServer2 service. These properties only affect the RapidMiner client interaction with the Hadoop cluster and do not affect any other applications that may use the HiveServer2 service. Use the hive.security.authorization.sqlstd.confwhitelist.append property (defined below) on the cluster side to enable setting additional properties beyond those defined in the built-in whitelist (see HIVE-8534). Use regular expressions for the enabled properties (see HIVE-8937).
If the property is empty on the cluster, the value shown below is a requirement for full RapidMiner Radoop functionality. If it already has a value, then its regular expression should be completed to include the following values. Changing this property requires a Hive service restart.
Set hive.security.authorization.sqlstd.confwhitelist.append to the following (the property value must contain no whitespaces):
radoop\.operation\.id|mapred\.job\.name|hive\.warehouse\.subdir\.inherit\.perms|hive\.exec\.max\.dynamic\.partitions|hive\.exec\.max\.dynamic\.partitions\.pernode|spark\.app\.name
The following table contains the list of the properties that the above regular expression defines. The table describes each property and the possible values that RapidMiner Radoop may set for it. It also describes how the software uses these properties. Please note that you do not have to set these properties, the table only lists the properties enabled by the regexp above.
| Property Name | Possible Values | Description |
|---|---|---|
radoop.operation.id |
random id | Helps to identify MapReduce jobs that belong to a certain Hive query. Most RapidMiner Radoop operators are translated into HiveQL queries. These queries are then usually translated into MapReduce code. When a RapidMiner user stops a process, the corresponding MapReduce job is killed. The software uses this property to find which job (owned by the user) should be killed. Not a Hadoop built-in property, this has no affect on Hadoop code. |
mapred.job.name |
job name | Sets the name of the MapReduce job that the current HiveQL query translates into. RapidMiner Radoop sets the job to the current operator name, allowing users to easily see which operator is currently running on the cluster. |
hive.warehouse.subdir.inherit.perms |
true |
Ensures that filesystem permissions inherit the parent user directory permissions. When data is transferred between Hadoop components (e.g., between Hive and (custom) MapReduce / Pig / Spark), Hive tables may be created inside the user directory on HDFS, but outside the Hive warehouse directory. |
hive.exec.max.dynamic.partitions and hive.exec.max.dynamic.partitions.pernode |
custom setting | Allows RapidMiner Radoop to use dynamic partitioning. This may be necessary when the user stores data in a partitioned table, or when Hive partitioning is used to partition the data in typical data mining workflows (Split Validation, for example). In these cases, you can use an advanced parameter to override the default limitation of dynamic partitioning on the cluster side. |
spark.app.name |
job name | In case of Hive on Spark, sets the name of the Spark job that the current HiveQL query translates into. |
Enable RapidMiner Radoop temporary tables
RapidMiner Radoop is not just a simple BI tool that uses Hive as a data source, it is also an advanced analytics tool that uses Hadoop as an execution environment. RapidMiner Radoop pushes jobs and queries down to the cluster for execution in Hadoop. To support complex analytics workflows, RapidMiner Radoop must be able to create new tables and store temporary results in Hive.
If the Hive user has no CREATE TABLE or CREATE VIEW privileges, or you do not want to allow creation of objects in the selected Hive database, create a sandbox database for RapidMiner Radoop:
- Provide only SELECT rights on the selected
other_databasesource objects. - Create a user-specific sandbox database (for example,
radoop_user_sandbox) owned by the Hive user. - Create views in the sandbox database on the
other_databasetables and views (for example,CREATE VIEW radoop_user_sandbox.view1 AS SELECT * FROM other_database.table1;)
Create/Drop functions
RapidMiner Radoop uses custom Hive UDFs. Creating or registering these functions requires the admin role. Otherwise, the permanent functions must be created manually by an admin. Further information can be found in the Installing RapidMiner Radoop functions manually section on the Operation and Maintenance page. Before running the function creation statements described on that page, ensure that you have run the following command to get the admin role.
SET ROLE admin;
RapidMiner Radoop supports HDFS encryption, with the following restrictions:
- If Radoop HDFS directory is located in an encryption zone, the user connecting to Hive database that is used by Radoop must have access to the encryption key. Furthermore, this directory must be located in the same encryption zone as the directory of the Hive database.
-
When dropping a Hive table stored in an encryption zone, the query should be issued using PURGE option:
DROP TABLE <table_name> PURGE;Some Radoop operators also execute DROP TABLE queries, these have a checkbox parameter that enables PURGE option.