You are viewing the RapidMiner Hub documentation for version 10.1 - Check here for latest version
RapidMiner StandPy
RapidMiner StandPy is an optional module for RapidMiner AI Hub which adds support for always-on Python interpreters to reduce latency. The module can be used as an alternative Python environment when embedding Python code into RapidMiner processes.
By default, RapidMiner starts a new Python interpreter for every Python operator embedded in a RapidMiner process. For most use cases this behavior is desirable as it guarantees complete script isolation and the 100-1000ms of overhead for initializing the Python interpreter are usually negligible.
There is however one exception: when deploying a light-weight process as web service this overhead is most likely not acceptable. It is this specific use case for which StandPy is designed to offer an alternative mode of running Python scripts.
The setup documentation consists of the following parts:
- Prerequisites
- Architecture overview
- RapidMiner AI Hub setup
- Connecting RapidMiner processes
- Limitations
- Troubleshooting
Prerequisites
RapidMiner StandPy requires RapidMiner AI Hub 9.9.2 or newer. In particular, you cannot use RapidMiner StandPy with the stand-alone distribution of RapidMiner Server or with RapidMiner Studio.
RapidMiner StandPy also requires the Python Scripting extension 9.9.2 or newer. The extension should be installed both in RapidMiner Studio and RapidMiner AI Hub (although the previous prerequisite ensures this automatically).
Architecture overview
The following simplified architecture diagram of RapidMiner AI Hub shows how two RapidMiner StandPy containers integrate into the existing infrastructure. At the very least you will need to deploy one container. Please note that all added components are part of a separate internal network:

All incoming requests for script executions go through the RapidMiner StandPy router component:
- A single router can be used with multiple containers.
- The router can be reached from other RapidMiner AI Hub components but is not reachable from outside RapidMiner AI Hub.
- The component can be used to set up additional authentication (optional).
- The router itself does not run any Python code.
The actual script execution happens in one of the RapidMiner StandPy container instances:
- Each container activates a single Python environment from the coding environment storage.
- The component manages one or more always-on Python interpreters.
- The containers and thus the Python interpreters do not have access to the main RapidMiner AI Hub network.
- The containers are stateless except for the Python interpreter states, i.e., containers do not persist submitted Python scripts.
This setup is designed to isolate the script execution from the rest of the platform. In particular, the authentication and the communication with other components is implemented in a container separate from the ones running the Python scripts.
However, the setup provides only limited protection from side effects caused by multiple scripts running on the same container. Containers do execute scripts in separate namespaces, but changes of global settings will affect subsequent runs. If side effects are a concern, consider using multiple RapidMiner StandPy containers, e.g., consider using separate containers for production deployments.
RapidMiner AI Hub setup
This section assumes you are using a Docker Compose based deployment of RapidMiner AI Hub using the templates provided by RapidMiner. If you are using another container runtime, please reach out to our support.
Let us assume we want to configure two RapidMiner StandPy containers as shown in the diagram above:
one for testing and one for a production deployment.
Both containers use the same Python environment named example-project-environment.
This section will walk you through the following steps:
- Checking Python environment dependencies
- Setting up the internal network
- Configuring the router
- Configuring the two containers
RapidMiner StandPy requires the environment dependencies to include up-to-date versions of the following modules. If you are extending a predefined environment, the modules are likely to already be installed:
dependencies:
- numpy
- pandas
- fs
- flask
- libiconv
- uwsgi
We can now edit the docker-compose.yml file for RapidMiner AI Hub.
To create the internal network for RapidMiner StandPy, we must add a single line to the end of the networks block.
Once added, it might look as follows:
networks:
rm-platform-int-net:
rm-idp-db-net:
rm-server-db-net:
rm-coding-environment-storage-net:
jupyterhub-user-net:
name: jupyterhub-user-net-${JUPYTER_STACK_NAME}
rm-go-int-net:
rm-go-proxy-net:
# Separate network for RapidMiner StandPy
rm-standpy-int-net:
We can now add the router to the services block:
rm-standpy-router-svc:
image: ${REGISTRY}rapidminer-standpy-router:1.0
hostname: rm-standpy-router-svc
restart: always
environment:
# List engines in format ENGINE_<ENGINENAME>_HOST:
- ENGINE_EXAMPLE_TESTING_HOST=standpy-container-testing
- ENGINE_EXAMPLE_PRODUCTION_HOST=standpy-container-production
# Optional security tokens in format ENGINE_<ENGINENAME>_TOKEN:
- ENGINE_EXAMPLE_PRODUCTION_TOKEN=secrettoken
# Limit the request size (no limit by default):
# REQUEST_SIZE_LIMIT=1m
networks:
rm-platform-int-net:
aliases:
- standpy-router
rm-standpy-int-net:
aliases:
- standpy-router
The configuration above sets up the routing for two containers named example_testing and example_production and protects the latter with a security token.
Take note that we added the service to both the platform network rm-platform-int-net and the separate network for RapidMiner StandPy rm-standpy-int-net that we have created in the previous step.
This is because the router will act as gateway between the two networks.
Next, we can add the two containers referenced above:
rm-standpy-container-testing-svc:
image: ${REGISTRY}rapidminer-standpy-container:1.0
read_only: true
tmpfs:
- /tmp
hostname: rm-standpy-container-testing-svc
restart: always
environment:
- CONDA_ENV=example-project-environment
# Optional number of worker processes (default 1):
- WORKERS=1
# Optional request timeout in seconds (default 30):
- TIMEOUT=45
# Restarts workers after the given number of requests. If not set,
# automatic restarts are disabled.
- MAX_REQUESTS=100
volumes:
- rm-coding-shared-vol:/opt/coding-shared:ro
networks:
rm-standpy-int-net:
aliases:
- standpy-container-testing
rm-standpy-container-production-svc:
image: ${REGISTRY}rapidminer-standpy-container:${RM_VERSION}
read_only: true
tmpfs:
- /tmp
hostname: rm-standpy-container-production-svc
restart: always
environment:
- CONDA_ENV=example-project-environment
# Optional number of worker processes (default 1):
- WORKERS=4
# Optional request timeout in seconds (default 30):
- TIMEOUT=5
# Restarts workers after the given number of requests. If not set,
# automatic restarts are disabled.
# - MAX_REQUESTS=100
volumes:
- rm-coding-shared-vol:/opt/coding-shared:ro
networks:
rm-standpy-int-net:
aliases:
- standpy-container-production
The two service configurations are identical except for their names and the environment variables.
The testing container only uses a single worker since throughput is most likely no concern. The timeout is relatively generous to allow for testing slow scripts. And finally, we force the single worker to restart after 100 requests to free any unused resources such as module imports that are no longer used.
The production container uses four workers to increase throughput. Let us assume we know from testing the scripts that all scripts should complete in under a second and that there is no memory build up. We can thus set an aggressive timeout to abort erroneous requests early and disable the periodic restarting of workers to prevent latency spikes.
Connecting RapidMiner processes
The Python Scripting Extension uses the connection framework for managing remote Python engines (RapidMiner StandPy containers). To configure a connection to the production container from the previous section, we need to create a new connection of type Remote Python Engine. As always, you can choose an arbitrary name for the connection itself:
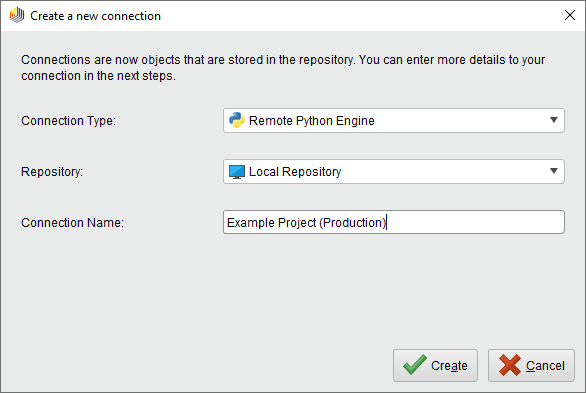
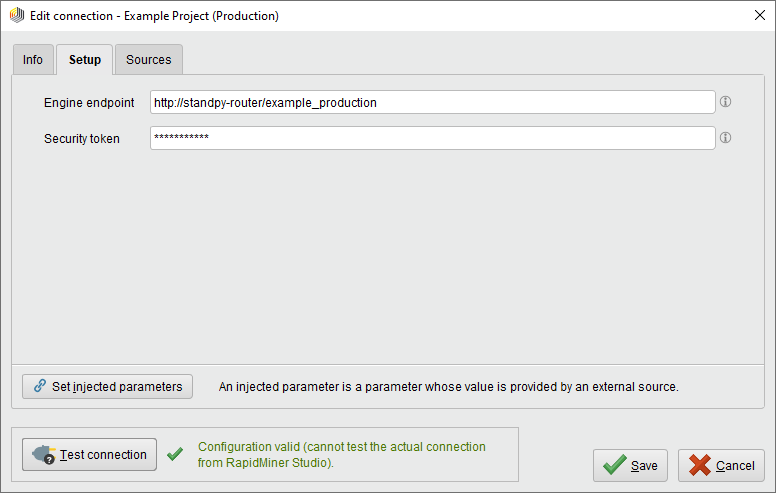
The configuration consists of only two parameters: the endpoint of the engine and the optional security token.
The endpoint is always a URL pointing to the RapidMiner StandPy router using the path to specify which container to use.
When defining the router service in the previous section, we gave it the alias standpy-router in the networks section.
Furthermore, we named the two containers example_testing and example_production.
Thus, we end up with the endpoints http://standpy-router/example_testing and http://standpy-router/example_production for the testing and production container respectively.
The security token is simply the token specified in the router service (if any).
Given that RapidMiner StandPy is only available from within RapidMiner AI Hub, we can only validate but not test the connection from RapidMiner Studio:
The configuration can be used with the Remote Python Context operator. This operator is a simple nested operator that takes a connection to a RapidMiner StandPy container as input and overrides the environment configuration of all embedded Python operators:
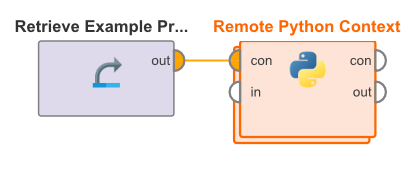
The operator has a single parameter named enable which enables or disables the environment override.
This way you can test processes in Studio without having to change your process structure.
You can test whether the StandPy connection is working as expected by scheduling a minimal process with three operators. Simply add an Execute Python operator inside the Remote Python Context shown above. For example, the following script prints the the prefix of the Python environment:
import sys
def rm_main():
print('StandPy testing:')
print(sys.prefix)
The prefix should end with the name of the Python environment specified for StandPy.
In our example, it should read /opt/coding-shared/envs/example-project-environment where example-project-environment is the name we have chosen in the previous section.
The print statement, or error messages in case the connection fails, will be shown in the process log.
Limitations
While RapidMiner StandPy is for the most part a drop-in replacement for the other Python environments, its web-service oriented architecture comes with some limitations: it is not a good fit for long running scripts and scripts might behave differently when working with files.
Long running scripts are a bad fit because there is no way to manually abort a script started in a StandPy container. The container will wait until the script completes or until the specified timeout is reached. In the latter case, the container will forcibly restart the entire Python interpreter.
In theory you can set the timeout to a very high value. But then you would risk erroneous jobs blocking the StandPy container for extended periods. However, in practice there should be no need for running long running scripts using StandPy, since in that case the overhead of the default script execution should be negligible.
RapidMiner StandPy does support file inputs but does not allow accessing the local file system.
File inputs are passed in as file-like objects of type TextIO.
Thus, most scripts should behave the same as if executed locally.
However, sometimes it is necessary to reopen an input file as BinaryIO.
To support such use cases, the input is stored in a temporary in-memory file system which allows closing and reopening the input.
Furthermore, StandPy replaces the builtin open function in the script's namespace with a compatible function that works on the in-memory file system.
For example, the following script will run as expected on StandPy:
import joblib
def rm_main(input):
# StandPy uses random strings for input file names:
file_name = input.name
# The open() function is replaced with a function aware of StandPy's
# in-memory file system, thus opening the file as binary will work:
with open(file_name, 'rb') as fp:
model = joblib.load(fp)
# ...
However, passing the file name to a function defined in another module is likely to fail:
import joblib
def rm_main(input):
# StandPy uses random strings for input file names:
file_name = input.name
# This call will most likely fail, since the joblib module will try to open
# the file using the builtin open() function:
model = joblib.load(file_name)
# ...
Thus, it is strongly recommended to always open files on the top level and pass on the file handles instead of the file names to functions defined outside the script.
Troubleshooting
A good starting point for troubleshooting are the process logs of the RapidMiner process that embeds the Python code. The Python Scripting extension logs the following information:
- Connection errors if the remote engine cannot be reached.
The Python traceback if the script execution fails. For example, a missing import will show up as follows:
INFO: Started operator : Execute Python May 17, 2021 7:33:25 AM com.rapidminer.extension.pythonscripting.operator.scripting.python.RemoteScriptRunner handleErrors SEVERE: Failed to parse the Python script Traceback (most recent call last): Script, line 3, in <module> ModuleNotFoundError: No module named 'missing'Print statements from the user script, for example:
INFO: Started operator : Execute Python May 17, 2021 7:40:02 AM com.rapidminer.extension.pythonscripting.operator.scripting.python.RemoteScriptRunner run INFO: A print statement from the Python script.Please note that print statements will only be logged if the script execution does not run into any error.
Further investigation will require administrator access to RapidMiner AI Hub. The following resources might help identifying issues:
Every StandPy container implements an
/infoendpoint. In the example above, queryinghttp://standpy-router/example_prodcution/infofrom within the AI Hub network will respond with:{ "environment": "example-project-environment", "max_requests": null, "timeout": 5, "version": "1.0.0", "worker_uptime": 762, "workers": 4 }The logs of the
rm-standpy-router-svcservice will list all requests that go through it. In particular, it will log failed requests, e.g., if the container cannot be reached or responds with an error code.RapidMiner AI Hub can be configured to forward external requests to StandPy. However, take note that such a configuration might expose unsecured Python containers and thus must not be allowed in production environments. To enable forwarding, search for the following block in the
.envfile# To enable standpy external access use this value as STANDPY_BACKEND # STANDPY_BACKEND=http://rm-standpy-router-svc/ STANDPY_BACKEND=http://standpy-is-not-enabled-by-default STANDPY_URL_SUFFIX=/standpyand change it as indicated in the comments:
# To enable standpy external access use this value as STANDPY_BACKEND STANDPY_BACKEND=http://rm-standpy-router-svc/ # STANDPY_BACKEND=http://standpy-is-not-enabled-by-default STANDPY_URL_SUFFIX=/standpyYou will need to restart the
rm-proxy-svcservice to apply the changes. Afterwards, you wil be able to connect RapidMiner Studio tohttp://<aihub-host>/standpy/<standpy-container-name>and to queryhttp://<aihub-host>/standpy/<standpy-container-name>/infofrom a local browser.