You are viewing the RapidMiner Hub documentation for version 10.3 - Check here for latest version
Best Practices for CI/CD
See also the best practices document for projects.
To effectively scale your AI initiatives, you need to create a system that allows for project revisions to be tested and released into production automatically—all without disrupting workflows at any other part of your enterprise. To help you do that, RapidMiner has established a series of best practices that are based on the agile programming methodology and adapted for data science projects.
In this document, we’ll share those best practices and explore how enterprises can use RapidMiner to set up a democratized data science development pipeline (CI/CD) in their organizations—allowing them to scale their AI initiatives while providing structure and safeguards to ensure production integrity.
RapidMiner AI Hub Environment Structure
Separating development and production environments is a core tenet of the software development lifecycle. Establishing separate environments is a proven way to encourage innovation and experimentation without having unexpected downstream consequences.
Due to the nature of RapidMiner's multipersona users, many of whom have no background in software development, we recommend three to four isolated, version-consistent AI Hub environments to support an agile yet secure overall architecture for your organization:
Env 1: Development (DEV)
This environment is typically used to safely build new processes, try out ideas, or change the data pipeline without affecting anything else. Project changes indirectly affecting workflows in a whole different place can be devastating for a company, so development usually takes place in a separate "sandbox" environment to avoid unnecessary risk. The resources for this environment tend to be standardized and solely depend on the number of active users. A general rule of thumb would be 10-20 active users per 64GB Unit. This environment does not guarantee uptime reliability and although backups are in place, rollbacks are uncommon; workflows and models are under version control to keep track of changes and experiments. It’s important to note that these limitations are expected and normal in sandbox environments. Permissioning on DEV is generous and encourages experimentation.
Env 2: Testing (TEST)
After a new project has been developed, it should undergo internal testing before being released. Testing can be further divided into phases like alpha or beta, and it is best practice to test in a semi-stable version without breaking DEV or PROD, commonly known as TEST or QA (i.e. Quality Assurance). This matches the “integration-test” phase of software engineering. This TEST environment uses samples of real-world data and processes to find potential flaws in the new deployment. Permissioning on TEST is generally similar to DEV, but it’s common for TEST environments to be "wiped clean" on a regular cadence to ensure a standardized testing cycle for all processes headed to PROD.
Env 3: Staging (STAGING)
This environment is a direct clone of PROD that’s used to test end-to-end deployment without affecting the PROD Hub. Permissioning is generally restricted and is updated regularly to ensure that it is always a 100% simulation of PROD. For AI Hubs running in a cloud infrastructure, e.g. AWS, Azure or GCP, it can be cost-effective to have this instance spun up and down as needed. Permissioning is extremely limited and uptime is guaranteed 99.99%+ while spun up.
Env 4: Production environment (PROD)
This AI Hub is primarily a read-only environment that runs processes to generate business value. Problems occurring in this environment are costing real money, so this should not be affected by any of the previous stages. For that reason, permissioning is extremely limited and uptime is guaranteed 99.99%+. Deployments are containerized with dedicated RAM/storage to ensure stability. Changes are infrequent and controlled.
A RapidMiner CI/CD Lifecycle
Here’s an example of what a typical RapidMiner CI/CD lifecycle looks like.
Note that under "B. Changes", the changes may be of two types:
- Changes to the software
- Changes to the machine learning models
One of the distinguishing features of machine learning development, as opposed to traditional software development, is the need for occasional retraining of the models to improve their performance in the face of new data. If, for example, the distribution of the incoming data has changed, no changes to the software may be necessary, but you will still need to update the model to maintain its performance.
A. Initial Deployment
Engineer Eddie, a RapidMiner-certified Data Engineer / Machine Learning Professional, builds a git-versioned RapidMiner project on DEV that he wishes to deploy. This could be model scoring consumed by an external webservice, a RapidMiner dashboard, RapidMiner alerting via email or SMS, scheduled ETL jobs that push data back into databases or Excel sheets, etc. This is considered 'beta' upon completion, and named
eddie-deployment-0.1.Eddie asks a colleague, Engineer Elizabeth, a RapidMiner-certified Platform Adminstrator, to review and test his deployment. Elizabeth provides feedback to Eddie and ensures that his deployment is safe, secure, well-documented, not overly resource-intensive, and consistent in design with other deployments throughout the organization. With the new changes applied, Elizabeth and Eddie agree that this is now
eddie-deployment-0.2.Eddie submits
eddie-deployment-0.2to System Administrator Sandra who oversees the entire CI/CD pipeline and has full admin access to both STAGING and PROD. Sandra, or someone on Sandra's team with the right permissions, loads Eddie's project into STAGING. She makes the final determination to deploy this project and decides what resources should be allocated.Sandra moves Eddie's project from STAGING to PROD and notifies Eddie that his deployment is now live as
eddie-deployment-1.0. She shares any relevant URLs and assigns permissions to Eddie so he can use the deployment as designed. Sandra adds this deployment to her list of other deployments that she monitors in PROD and sets up alerts as needed. Sandra also schedules an audit in 3 months with Eddie to evaluate his deployment.
B. Changes
At some point after deployment, Eddie wishes to makes some improvements to one of his processes. He works in DEV and commits
eddie-deployment-1.1to his project repo.Eddie goes through the exact same stages as when he initially published his deployment. However this process will be faster as most of the project remains unchanged. If successful, Sandra notifies all users of
eddie-deployment-1.0that it will be upgraded at a time and date to minimize overall impact to generated business value. When live, this is noweddie-deployment-2.0.
C. Quarterly Review
Three months after going live with the most recent revision eddie-deployment-2.0, Sandra and her team meet with Eddie and other users of this deployment. They review the performance and resource allocation. If code changes are recommended, Eddie follows the procedure as shown in B. If the review recommends deprecation, he follows the procedure outlined in Section D.
D. Deprecation
During a quarterly review taking place 18 months after the initial deployment, Sandra and Eddie agree that his deployment is no longer generating business value and should be deprecated. Analyst Alyssa has been working a new solution to this business problem and is ready to start the process to move her deployment, alyssa-deployment-0.1, from DEV to TEST. Sandra alerts all existing users of
eddie-deployment-2.0that it will be deprecated on a certain date and time – far enough ahead so that adjustments can be made for time-critical applications.At the designated date and time, Sandra removes
eddie-deployment-2.0from PROD and archives the process and all logs for audit purposes. She moves the resources to the general pool to be used by another deployment.
Administrative Tools for Project Deployment
All processes, ExampleSets, and associated objects that will eventually be deployed should always reside in a RapidMiner project. Technically, these projects are git-backed, so the deployment to a different environment is equivalent to a "clone / copy / push" operation in git.
Remote access and control of the AI Hub is possible to automate tasks, including access to projects. This is realized through a REST-API.
The Admin Extension
To fully embrace the no-code approach even with advanced topics like this, the Admin Extension was created. With just a single operator, users can deploy projects from one AI Hub to another completely within the RapidMiner ecosystem.
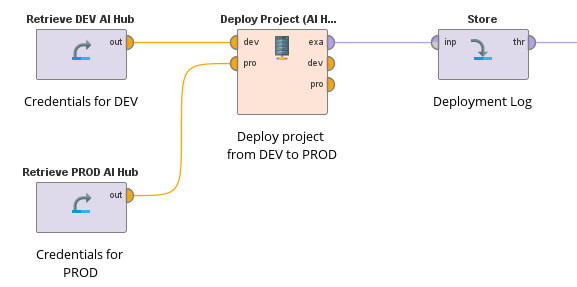
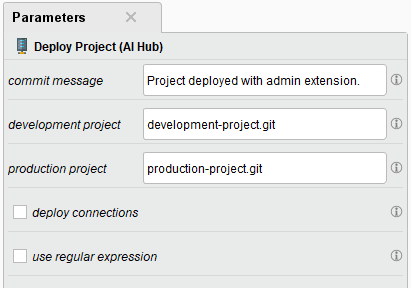
Users will need connection credentials with appropriate privileges of both AI Hubs (e.g. from DEV to TEST) to create specialized AI Hub connection objects. These are the inputs of the operator, the source and target project are defined in the parameters panel.
Since different environments usually have different data sources (e.g. databases), administrators should consider not deploying connections, but rather creating connections with the same name pointing to the appropriate data source for the new environment.