You are viewing the RapidMiner Server documentation for version 8.0 - Check here for latest version
What's new in RapidMiner Server 8.0
This page describes the new features of RapidMiner Server 8.0. Please notice that there are significant architectural changes from the 7.x versions. Carefully read this document and the installation guide before migrating your existing environments.
New fully scalable Architecture!
Big changes in this release: the new RapidMiner Server has a scalable and more robust architecture. This graph shows a component-view:
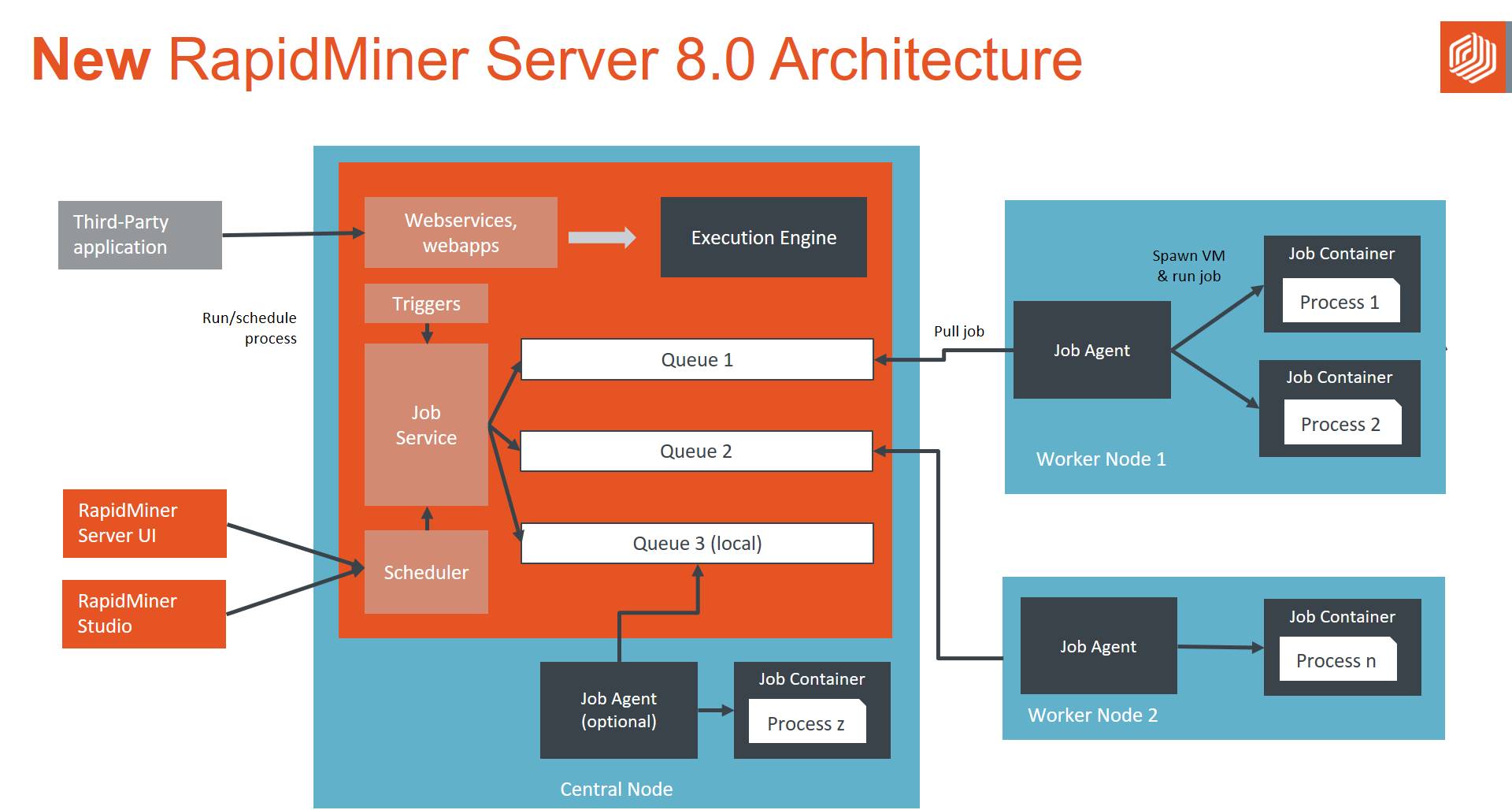
Each blue box represents a separate machine. The big box to the left represents the central RapidMiner Server, which provides the UI and single point of entry for user requests. These tasks are carried out within the RapidMiner Server central node:
- Scheduling of user jobs (processes)
- User, queue and permissions management
- Execution of processes running on the local Job Agent (this Job Agent is deployed and configured by default, but it can be removed if the user prefers that all execution is done remotely)
- Execution of processes scheduled through web services, web apps
The Job Agents are the new kids on the block. They can be deployed in remote machines and they are configured to point to one queue each. Job Agents check their queue and, if there are jobs to do, pick them up, spawn a Job Container, and execute the job (user process). Their role is to provide the scalability and, together with the queues, the resource sharing and management among users or projects.
Although scalability is the main new feature, it's still possible to run the RapidMiner Server in a single machine with one (or more) local Job Agents executing the jobs. In that case, the new architecture provides better fault tolerance and improved reliability.
Components
There are two components:
RapidMiner Server – includes all the services the older RapidMiner Servers provided, including scheduling, queues, web services, triggers, etc.
RapidMiner Job Agent – can be deployed on any local or remote machine for horizontal scalability. It needs to be configured to point to one of the queues defined in the RapidMiner Server. It's only responsibility is to pick up jobs from the queues and run them.
Process and data flow
When a user schedules a process from Studio or from the Server's UI, the process is placed into the corresponding queue. Any of the Job Agents connected to that queue pick up the work and run the process. The RapidMiner Server (and the user, through the UI or Studio) gets notified and logs become available.
The process execution is the responsibility of the Job Agent. It spawns a Job Container, which may connect to the repository or external data sources as needed depending on the process. There is no data flow from the Server to the Job Agents or the other way around.
Queues and Scheduling
Differently from what happened in previous versions, queues are now linked to Job Agents. Multiple Job Agents can connect to the same queue, but each Job Agent can only connect to one queue. Queues have user permissions and sending a process/job to a queue determines which Job Agents will work on it and which resources will be available for it. Many processes can be run in parallel by a single Job Agent if it's configured to start a certain number of Job Containers. However, a single process is always run by a single Job Agent (a process execution cannot be distributed to multiple machines).
If no free resources are available when a process is scheduled, it waits in the queue until it is picked up by any free Job Agent.
What doesn't change
This is a first step in the direction of creating a better architecture for all use cases. In this first release, we have focused on improving scalability and reliability for long running processes. As you can see in the architecture graph, processes being run as web services or WebApps are still executed in the Central Node of RapidMiner Server; that's still not scalable. With the current architecture, Job Agents still have some increased latency as they spawn a Job Container for every job they have to run. Therefore, we recommend big, long-running jobs be scheduled in the Job Agents, while fast, short jobs run as web services.
Main differences between the old and the new RapidMiner Servers
This table shows some of the main differences you will find in the new version.
| RapidMiner Server 7.6 | RapidMiner Server 8.0 | |
|---|---|---|
| Scalability | Limited to one machine | Single central Server for scheduling and administration, but multiple Job Agents that can be installed on multiple machines for process execution. |
| Queues | Just for logically organizing jobs | Each Job Agent is configured to only one queue (but each queue can be connected to multiple Job Agents). Job Agents are configured to use certain resources (memory and processes). Those resources become available for jobs scheduled in the corresponding queue. Therefore, queues are a means to share and limit the system's resources among users. |
| Resource Management | Everything shares the same HW resources. | The new queues allow having dedicated machines or resources for groups of users |
| More on Resource Management | Jobs can take up as many resources as they need up to the capacity of the machine. | Job Agents provide access to the resources (memory and CPU). By configuring the queues, Administrators can increase or limit the resources available to a user or group. They can be shared or be restricted to a group. |
| Web Services, and WebApps | Run on Server | Run on Server, too. They are not affected by the new architecture. They are not run on Job Agents. |
| Scheduling | Jobs run as soon as they are requested or whenever they are scheduled. They always run on the Server. | Jobs will be run on any Job Agent with free resources connected to the queue. If there are no free resources, jobs are queued. |
| Logging | All logs are written and stored in the Server's file system. | Logs remain in the (possibly remote) Job Agents. They can be retrieved from the central RapidMiner Server as long as the Job Agent is running. |
| UI | First steps were taken towards a fresh new UI design of RapidMiner Server. The way the process list is shown and how queues are created have been renewed. | |
| Extensions/JDBC drivers | Deployed on the RapidMiner Server | They have to be manually deployed on every Job Agent. Each Job Agent may have a different list of extensions, so it’s possible to create dedicated Job Agents for a particular use case. |
| Fault tolerance | Everything runs on a single machine and a single JVM. Problems in a process can affect the whole system. | Executions are run on separate JVMs and (potentially separate machines). All processes are fully independent and the whole system becomes much more robust and tolerant to problems in individual processes. |
Enhancements and bug fixes
The following pages describe the enhancements and bug fixes in RapidMiner Server 8.0 releases: