You are viewing the RapidMiner Radoop documentation for version 8.1 - Check here for latest version
SparkRM: Process Pushdown
Single Process Pushdown and SparkRM are meta operators that run their subprocesses on one (Single Process Pushdown) or multiple (SparkRM) Hadoop cluster nodes.
The subprocesses in the meta operators can contain any core operator from the RapidMiner Studio. Furthermore, external extensions (e.g. Weka, Text Processing) can be used as well, they are automatically uploaded to the cluster by the client (Studio or Server). A few operators, such as operators related to database handling and the Execute Script operator, are not supported at the moment. You can also set non-default Preference Settings for RapidMiner Studio or any extension by setting the configuration parameters parameter. This is particularly useful e.g. when using the Python Scripting extension where the Python installation directory must be provided via a Preference Setting.
For both operators you can set sampling for your data (disabled by default). Macros can be used, created and manipulated by the inner operators and the Samples repository can be referred to in the subprocess.
Single Process Pushdown
Single Process Pushdown accepts an arbitrarily large HadoopExampleSet on the first input, and any IOObject on the subsequent input ports. Likewise, it delivers a large HadoopExampleSet on the first output and any IOObject on the other output ports.
Please note that only the first input/output port can handle big data, the other ones store the objects temporarily in the client machine’s memory, therefore, they should only be used for models, performance vectors, small tables, etc.
Further considerations about the operator's ports and parameters can be found in the RapidMiner Radoop Operator Reference (PDF). The Samples repository is accessible via a Retrieve operator in the subprocess, other repositories are not, so they must be connected to one of the operator input ports.
The following example process demonstrates the power of the Single Process Pushdown operator:
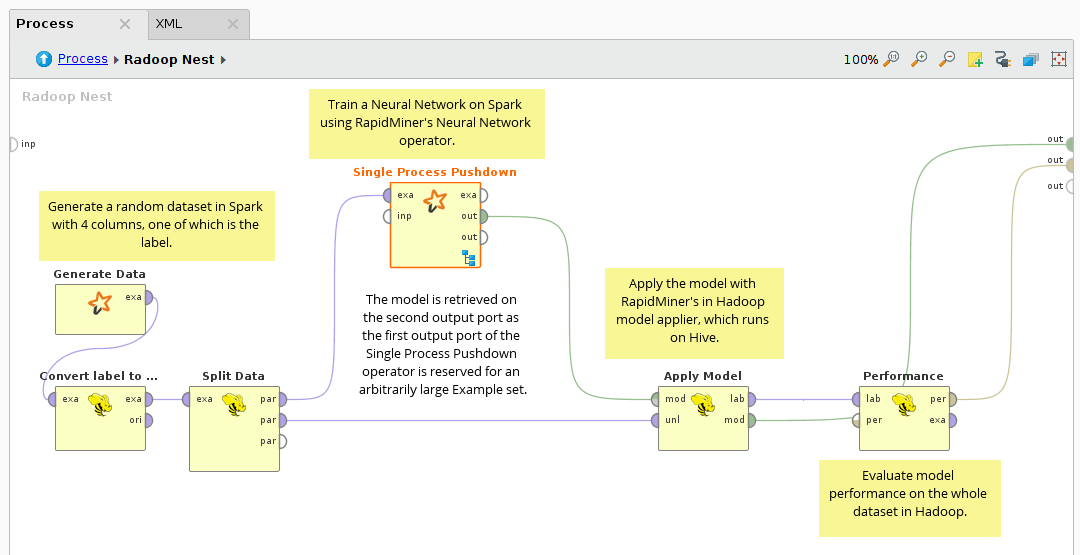
The subprocess inside Single Process Pushdown:
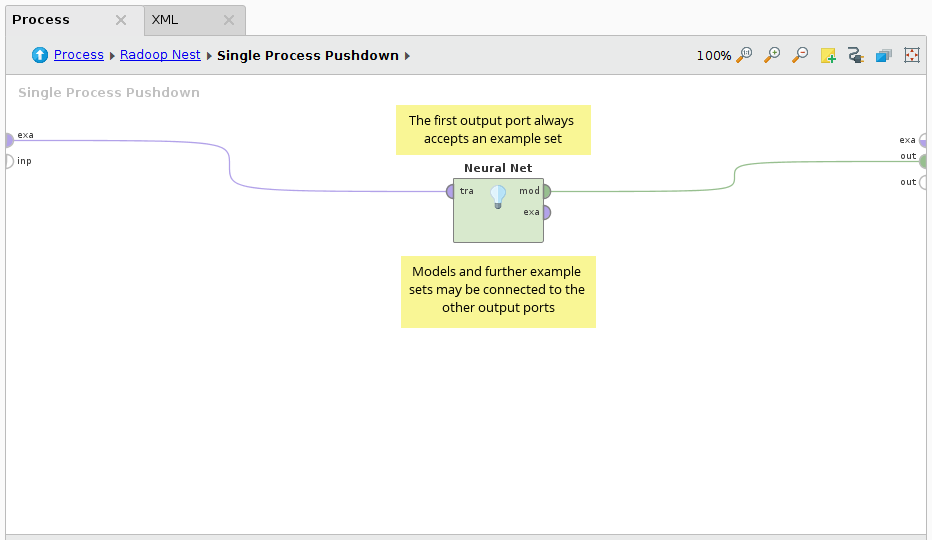
The neural net is one of the most accurate learning algorithms. In this process, RapidMiner's Neural Net operator is used on the input HadoopExampleSet, which is generated using the Generate Data operator. As the label is always numerical, it is casted to binominal first. Split Data is used to create the training and the testing dataset. The Neural Net operator is used inside the Single Process Pushdown to build the model. In the last step, the neural net model is applied on the testing data with RapidMiner Radoop's distributed Apply Model operator and the Performance vector is calculated.
SparkRM (Parallel Process Pushdown)
The SparkRM meta operator is the most unique operator of RapidMiner Radoop. It is capable of executing a RapidMiner process in parallel using multiple cluster nodes.
Just like Single Process Pushdown, the operator has an Example Set input port and an Example Set output port (the first input and output ports). The operator accepts an arbitrarily large HadoopExampleSet on this input and can deliver a large HadoopExampleSet on this output. The other input and output ports of the operator are for further IOObjects (models, performance vectors, small ExampleSets, etc.).
Please note that only the first input/output port can handle big data, the other ones store the objects temporarily in the client machine’s memory, and they are also distributed to all partitions during execution. Therefore, those ports should only be used for models, performance vectors, small tables, etc.
The core concept of SparkRM is the partition. When the operator is executed, the data on the first input port is split up into partitions based on the operator's partitioning mode and related parameters. The subprocess is then executed on all of these partitions, preferably in parallel (to the extent as the cluster resources allow). Multiple cluster nodes can be used to execute the process in parallel and one cluster node is able to process multiple partitions in parallel. The following partitioning methods are available:
- Linear: This is the default partitioning mode. When linear partitioning is used, the number of partitions is proportional to the size of the input data. The size of one partition is based on the size of an HDFS block on the cluster. Use this partitioning mode if you don't want to specify the exact number of the partitions and have no preference over the distribution of the data between the partitions. This is the fastest partitioning mode, because data movement is minimized, the data is preferred to be processed where it is stored.
- Random: If you select the random partitioning mode, you can specify the size of each partition (if partition sizing is set to Absolute sized partitions) or the number of partitions (if partition sizing is set to Fixed number of partitions). Use this partitioning mode if you need to know the number of partitions, but have no preference over the distribution of the data between the partitions. The random partitioning mode redistributes the data to create the desired number (or size) of partitions, thus, it is expected to have a larger overhead than the linear partitioning mode.
- Attribute: The attribute partitioning mode lets you specify the distribution of the data between the partitions. The input data is grouped based on the partitioning attribute, so that each partition receives the data for one unique attribute value. In this case each Example has to be moved to a specific node, which results in significant network traffic. Use this partitioning mode if you want to execute the subprocess on exact groups of the input data. Please note that the performance is suboptimal for unevenly distributed data, as one partition may contain more examples than the other.
On each of the operator's IOObject output a collection is created containing the outputs of all partitions. Obviously, this means that the size of the IOObject collection equals the number of partitions that were used in the process. On the main (first) Example Set output, you can choose between two behaviors. The merge output parameter determines whether each partition's output should be merged into a single HadoopExampleSet (recommended and default value) or a collection of HadoopExampleSets should be created. By default, if the output is merged, the process will fail if different partitions generate ExampleSets with different schemas. If you want to avoid that, please enable the resolve schema conflicts parameter - in this case the union of the output schemas is delivered, and the data gaps (where one partition has a value, but another has not) can either be filled with missings or a specified value. Please note that if the merge output parameter is unchecked, Radoop creates a Hive table on every element of the collection. Managing a large number of Hive tables causes an overhead and may hit the limitations of HiveServer2. Thus, we encourage you to use only a moderate number of elements in this collection, when merge output is unchecked.
The following example demonstrates a simple use case for the SparkRM operator via using just sample data for simplicity.
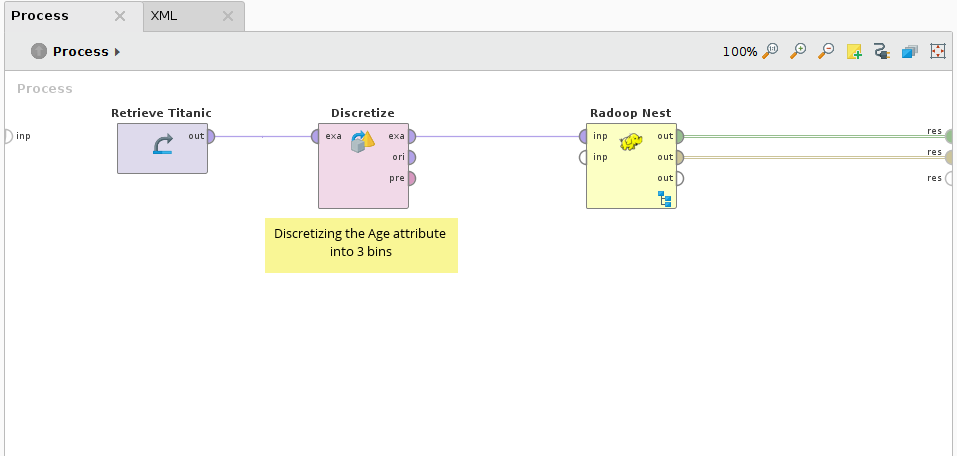
First the Titanic sample dataset is retrieved and the Age attribute is discretized into 3 bins. This results in 4 different values in the Age attribute: range1 [-∞ - 26.778]; range2 [26.778 - 53.389]; range3 [53.389 - ∞] and the missings. Please note that it is not recommended for real life use cases to use RapidMiner Radoop operators on data that fits in RapidMiner Studio's memory (like the Titanic dataset). If you have big data, use Radoop's Retrieve (recommended) or Read CSV operators inside the Nest to access your input.
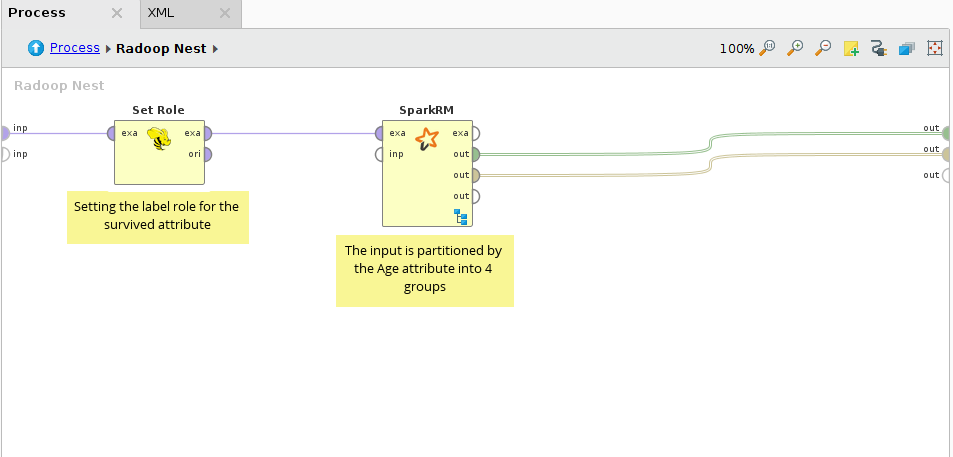
In the Radoop Nest the survived attribute is specified as the label, and the data is connected to the first (Example Set) input port of SparkRM. For the SparkRM operator attribute partitioning is set and the discretized Age attribute is set as the partitioning attribute. This results in 4 partitions. We expect to build different predictive models for the different age categories.
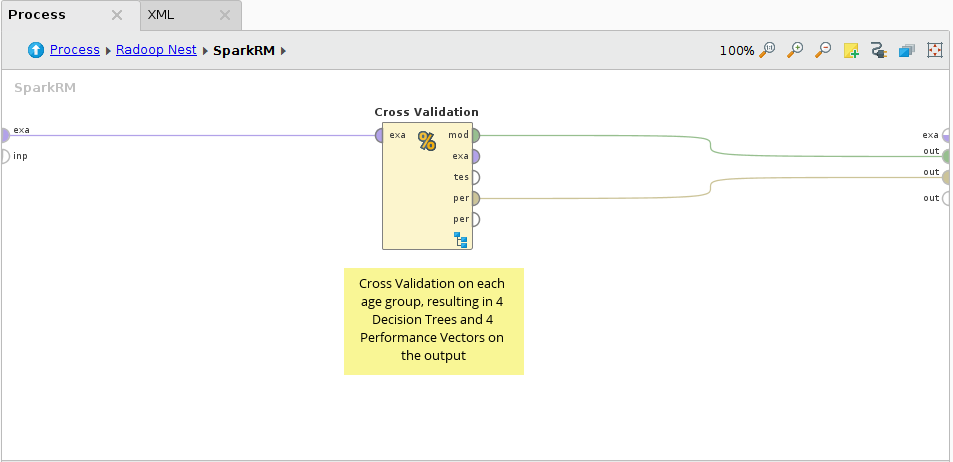
In the pushdown process Cross Validation with a Decision Tree modeler is performed on the 4 partitions in parallel. On SparkRM's output only two IOObject output ports are used, the Example Set output is not connected, because we do not alter the dataset, just build models on it (on its partitions).
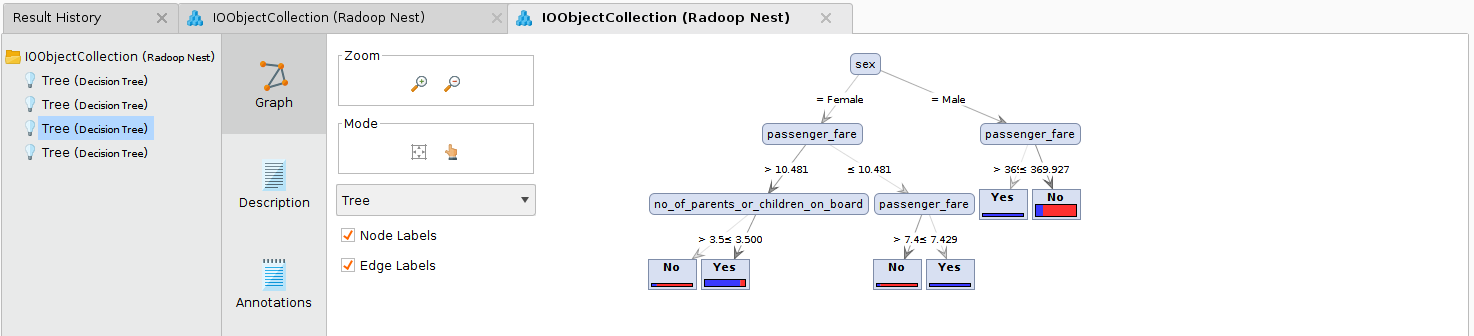
On the connected outputs a collection of Decision Tree models and another of Performance Vectors are delivered. Each collection contains 4 elements, that can be examined on the Result view of Studio.
Advanced settings and monitoring
When running a Spark application, you usually need to specify the required memory and core that it will use on the Hadoop cluster. Radoop uses a custom resource heuristics when submitting your process. This works well with the default settings for most use cases, but adjusting or turning off the heuristics is also possible. For more information please refer to the help panel of the operators.
Note that Spark usually executes a failing RapidMiner process again in order to tolerate Hadoop cluster errors. But this may also cause that there is an unnecessary re-run in case there is a process error your subprocess. Radoop prevents this re-runs only, when the error occurred is obviously a user error or process setup error. Otherwise, the default number of trials is the value of the yarn.resourcemanager.am.max-attempts on the cluster, however, this value can be overridden via the spark.yarn.maxAppAttempts Advanced Spark Setting.
By default, the Single Process Pushdown and SparkRM use a memory monitor in order to detect and kill its subprocess when it runs out of memory. The memory monitor can be configured in the Property Settings panel. If this feature is disabled, the process may stuck in the RUNNING state for a long time before it fails with an out of memory error. Note: because of a known Spark error, the memory monitoring service may not work together with SparkRM's attribute partitioning mode. Please turn off the memory monitor in this case, as the error message recommends.