You are viewing the RapidMiner Radoop documentation for version 9.0 - Check here for latest version
RapidMiner Radoop Basics
After installing the RapidMiner Radoop extension, you can see the Hadoop Data view:

The Hadoop Data view is a powerful tool for managing your data on the Hadoop cluster. Later in these pages, it is discussed in detail.
This section describes the main concepts required to design processes that run on your Hadoop cluster. Since Apache Hive is part of the solution, these explanations often refer to basic Hive concepts like tables or columns. If you are unfamiliar with Hive, think of it as a (distributed) relational database or data warehouse infrastructure over Hadoop. It understands SQL and translates input to distributed jobs.
Understanding the Radoop Nest operator
Radoop Nest is the most important building block in RapidMiner Radoop. Every process must contain at least one Radoop Nest (meta) operator; it specifies the connection to the Hadoop cluster.
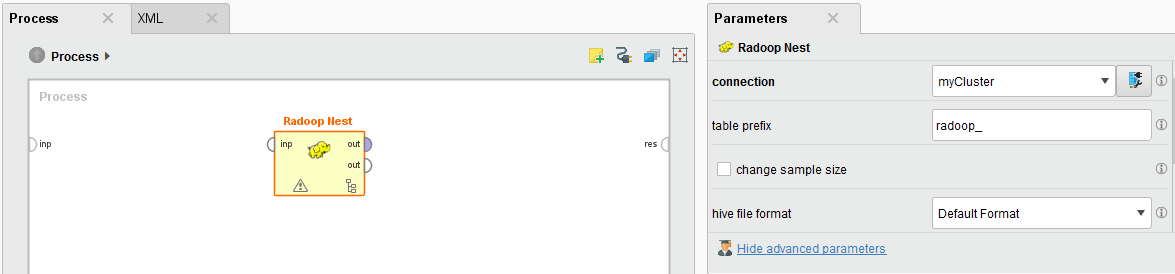
Any subprocess of Radoop operators put inside the Radoop Nest describes the process that runs on that Hadoop cluster; all content outside the nest (processed by RapidMiner Studio operators) is processed in memory. When you design a process, you will not notice any difference between these two sets of operators in their basic structure — inputs, outputs, and parameters. Most Radoop operators have a RapidMiner Studio counterpart. The main difference between the two is that the Radoop operators have a minimal memory footprint and always keep and process data on the cluster.
Radoop Nest parameters
You define cluster connection details in the connection parameter of the Radoop Nest operator. If you change this parameter, the client immediately tests the connection (indicated by a progress bar in the lower right corner) and raises a warning if the connection test fails.
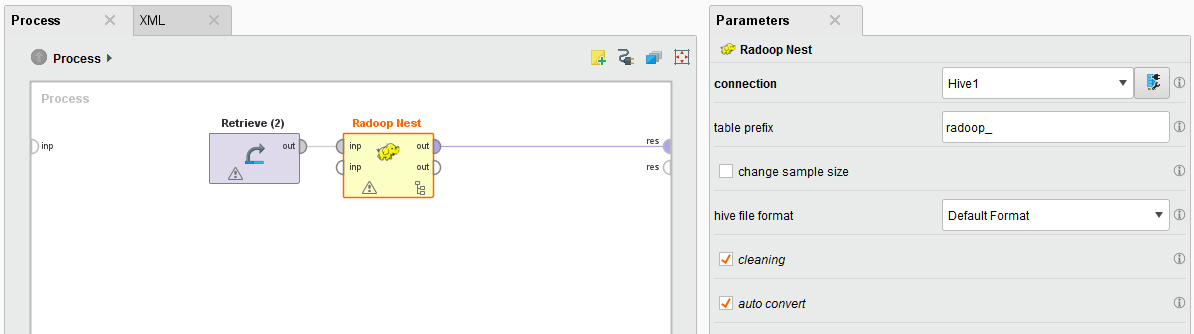
Additional parameters of the Radoop Nest operator:
| Parameter | Description |
|---|---|
| table prefix | During a process run, Radoop creates temporary objects in Hive. The object names start with the prefix defined with this parameter. You can allow user-specified prefixes during process design or set a default value for this parameter with the table.prefix global property. |
| change sample size | Overrides the output sample size for this subprocess. By deafult this parameter is set to false which means that the sample_size.overall property determines the sample size. |
| sample size | Sample size for Hadoop data sets on the Nest output; zero uses the full sample. This option is only available if change sample size is checked. |
| hive file format / impala file format | Defines the storage format for Hive tables to use inside the nest. This setting applies to both temporary and permanent Hive tables, although you can override the storage format of permanent tables with the Store in Hive and Read CSV operators. By default, the storage format is not specified and Radoop uses the Hive server or Impala default settings (usually TEXTFILE format). You can explicitly define TEXTFILE as the format, which has the advantage of providing human-readable data to the distributed file system. Change this parameter if you want to use more advanced file formats for optimized performance (smaller size and faster processing). |
| Impala connections only: reload impala metadata (advanced parameter) | Calls invalidate metadata statement on the selected tables or the whole database if tables are not specified. This reloads the metadata in Impala from the Hive metastore so you can use all Hive tables and views in your process. |
| Impala connections only: tables to reload (advanced parameter) | Call invalidate metadata on certain tables or the whole database if tables are not specified. Consider setting this parameter if your database contains a large number of tables. |
| cleaning (advanced parameter) | Defines whether Radoop should delete temporary objects after a process finishes. The default behavior (true/checked) deletes the objects, which is highly recommended since your cluster could soon fill with temporary objects. You may want to uncheck this for a short period, for example to debug a process. You can easily delete these objects afterwards. |
| auto convert (advanced parameter) | If true/checked (the default), data sets consumed at Radoop Nest input ports (and stored in operative memory) are immediately pushed to the cluster. Data is written to a temporary Hive table and is ready to serve as operator input inside the nest. If set to false/unchecked, only operators inside the nest write data to the cluster (usually when they consume it on their input ports). In this case you can also operate on in-memory data sets inside the nest, but you rarely need to do this. |
Radoop Nest input
Radoop allows you to combine memory-based and cluster-based operators in the same process. On its input port, Radoop Nest imports data from the client's operative memory to the cluster. The operators inside the nest consume and produce HadoopExampleSet objects (the cluster-based variant of the standard ExampleSet object). The HadoopExampleSet stores the data in Hive, in a temporary or permanent table or view, and has a minimal footprint on the client's operative memory. You can, of course, also process data that already resides on the cluster or import data directly to the cluster so that you do not have to use any of the Radoop Nest input ports. Instead, just access or import the data in a subprocess. The following is an example of a subprocess inside Radoop Nest.
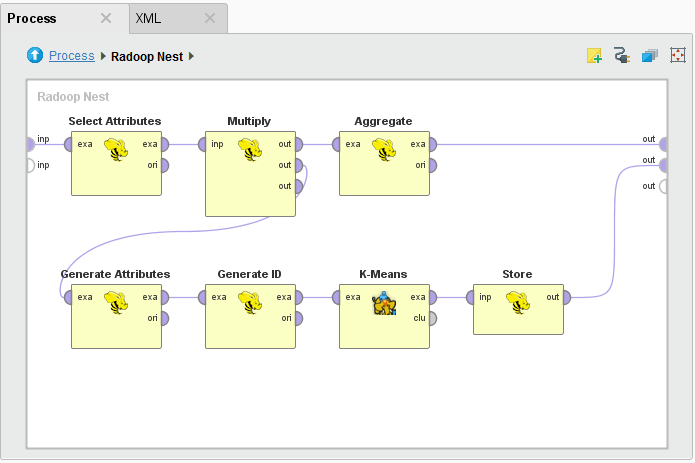
Radoop Nest output
Radoop Nest can have any number of output ports to deliver the memory-based ExampleSet objects directly to a process output port or to the input port of the next RapidMiner operator outside of the nest. You can connect an operator inside Radoop Nest to the nest's output port. Radoop fetches the data or a data sample from the HadoopExampleSet output to the client's operative memory and it then propagates further as a memory-based ExampleSet on the process flow. Because the data sample must fit into operative memory, you may want to work on aggregated data (after the aggregation took place on the cluster). You can limit the number of rows for the fetched data sample using the sample_size.overall property or the sample size parameter of the nest.
Running a process
The process can be started using the ![]() Run button in the main toolbar. Status icons in the bottom left corner on the operators and progress indicators can provide assistance regarding the process execution. Note, however, that there can be more operators with active progress indicator simultaneously. This is because Radoop operators usually create only Hive views, and postpone calculations. Because of the intensive computation, distributed jobs (e.g., MapReduce jobs) only happen when the HadoopExampleSet is materialized (a Hive table is generated for it and the (sometimes temporary) data is written to the HDFS). This is only done when necessary or when the optimizer algorithm decides to do so.
Run button in the main toolbar. Status icons in the bottom left corner on the operators and progress indicators can provide assistance regarding the process execution. Note, however, that there can be more operators with active progress indicator simultaneously. This is because Radoop operators usually create only Hive views, and postpone calculations. Because of the intensive computation, distributed jobs (e.g., MapReduce jobs) only happen when the HadoopExampleSet is materialized (a Hive table is generated for it and the (sometimes temporary) data is written to the HDFS). This is only done when necessary or when the optimizer algorithm decides to do so.
RapidMiner-to-Hive data type conversion
The terms attribute and column are interchangeable in this document, since an attribute in RapidMiner can be a column of a Hive table or view on the cluster, and vice versa. The following two tables match RapidMiner and Hive data types.
The first table shows the conversion that takes place during an ExampleSet import; the second table shows the conversion that takes place when the data is fetched from the cluster to operative memory. Note that table and attribute names may change slightly inside a Radoop Nest— identifiers are automatically converted to lowercase, special characters are replaced by underscores, and, to avoid collision with certain reserved words in Hive, an underscore suffix is appended to some terms. For example, an attribute with the name "Column" in RapidMiner becomes "column_" inside the Radoop Nest (because "COLUMN" is a keyword in the Hive Query Language). You can easily track these changes at design time by checking the metadata propagation.
Conversion to Hive data type
| RapidMiner data type | Hive data type |
|---|---|
| integer | bigint |
| real | double |
| numerical | double |
| binominal | string or boolean |
| polynominal | string |
| nominal | string |
| date | string |
| other | string |
Conversion to RapidMiner data type
| Hive data type | RapidMiner data type |
|---|---|
| tinyint | integer |
| smallint | integer |
| int | integer |
| bigint | integer |
| decimal | real |
| float | real |
| double | real |
| boolean | binominal |
| string | nominal |
| other | nominal |
RapidMiner maintains a nominal mapping for nominal attributes. This internal data structure maps nominal (string) values to double values for efficient memory usage. Since the process inside the nest runs on the cluster and must have a minimal operative memory footprint, Radoop does not maintain this structure (although it does for binominal attributes). However, when Radoop Nest delivers a data set on its output port fetched from the cluster, nominal mapping can be rebuilt by subsequent operators of the process. To do this, pay attention to notes about nominal attributes usage in the core operator help text. The nominal mapping for binominal attributes also indicates which string value is considered as the positive value out of the two possible string values.
RapidMiner Radoop operators
In addition to Radoop Nest, which is the container for the subprocess on the Hadoop cluster, there are a many RapidMiner Radoop operators that can run inside the Radoop Nest. These operators are categorized into the following groups:
- Data Access
- Blending
- Cleansing
- Modeling
- Scoring
- Validation
- Utility
These groups are described in more detail in the section describing operators.
Breakpoints
During process design, you may want to examine intermediate results. To do so, you can define breakpoints before or after any operator and examine the objects on the input or output ports. For operators inside the Radoop Nest, since they store data on the cluster, you can fetch a data sample to operative memory for each HadoopExampleSet object and examine it in the same way as for any other ExampleSet object. Metadata and data shown in the Charts and Advanced Charts panels provide highly configurable tools to visualize the data. You can control the maximum size of these data samples by setting the Sample size breakpoint property.
Note that using a breakpoint results in data materializing on the cluster at the point where the breakpoint pauses the process. This means that the computation may take place earlier than without the breakpoint and may use more space on the HDFS. Similarly, total run time with a breakpoint may be longer than the time required for the process to complete without breakpoints. Consider this as standard debugging overhead.