You are viewing the RapidMiner Studio documentation for version 9.7 - Check here for latest version
The Design View
See also the video introduction to the RapidMiner GUI.
RapidMiner Studio is a visual workflow designer for predictive analytics that brings data science and machine learning to everyone on the analytics team.
When you're working on a new project of any kind, often the first step will be to go to a whiteboard, where you will plan the workflow and identify the key steps on the way to your goal. If you're a data scientist, the workflow will usually include one or more of the following steps:
- Import data
- Prepare data
- Build a model
- Validate the model
- Apply the model
RapidMiner Studio implements your whiteboard workflow in software, in the Design View. The Design View includes numerous panels.
- Data, processes, and results are stored in the Repository.
- The essential elements of every workflow are called Operators.
- Operators are connected via ports. The output of the first is passed as input to the second.
- A connected set of Operators that help you to transform and analyze your data is called a process.
- The behavior of an Operator can be modified by changing its parameters.
- The behavior of an Operator can be understood by reading the Help.
Each of these terms will be examined in more detail below.
The default view
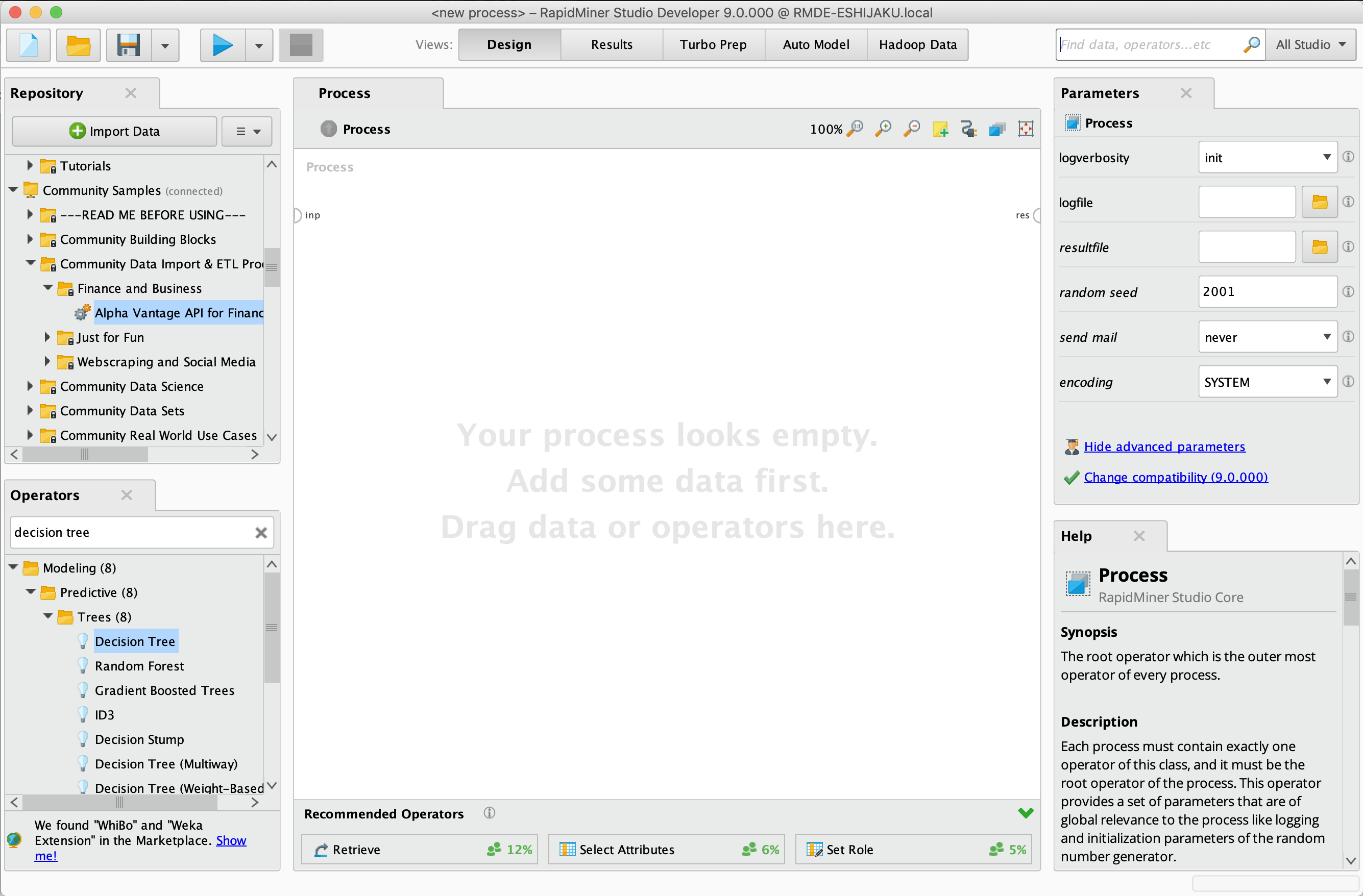
Process
Process: A connected set of Operators that help you to transform and analyze your data.
Also known as: flow, program, pipeline, diagram
Your goal is to create a finished process, a connected set of Operators that produce a result.
For example, your process might read a data set and build a predictive model.
When you have connected all your Operators and set their parameters,
press the Run ![]() button at the top of the user interface,
and the results will be displayed in the Results View.
button at the top of the user interface,
and the results will be displayed in the Results View.
As discussed in Run a Process, there is more than one way to run your process. You can run it:
- locally
- in the background
- on RapidMiner AI Hub
- on RapidMiner AI Hub, as a scheduled process
As your processes grow in size, you will need some way to manage their complexity.
- You can hide the complexity, by moving groups of Operators into a single
SubprocessOperator. - You can run a process from within another process, via the
Execute ProcessOperator.
To save your process to a Repository, select File > Save Process from the main menu.
You can easily share a process by first exporting it to an XML file:
- to export the process, select
File>Export Process. The export dialog allows you to save the file as.rmpor.xml; in reality, both these file formats are identical (XML). - to import the process, select
File>Import Process.
Ports
To build a process, you must connect the output from each Operator to the input of the next via a port. To connect two ports, click on them. Hover a port to see a tooltip with additional information. When connecting two Operators, you need to make sure that the output port of the first is compatible with the input port of the second, or you will get an error message. The input and output ports for each Operator are described in the Operator Help, and a complete list of ports is given in the Getting Started Glossary.
If you want to see the results in the Results View, you must connect the last Operator in a process to the results port ("res") on the right side of the Process Panel.
Hint: double-click on an output port, and it will be connected to the next available results (“res”) port.
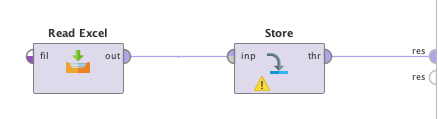
The following example shows a simple process, where the data from an Excel file is (1) read, (2) stored in the Repository, and (3) displayed in the Results View.
A simple process
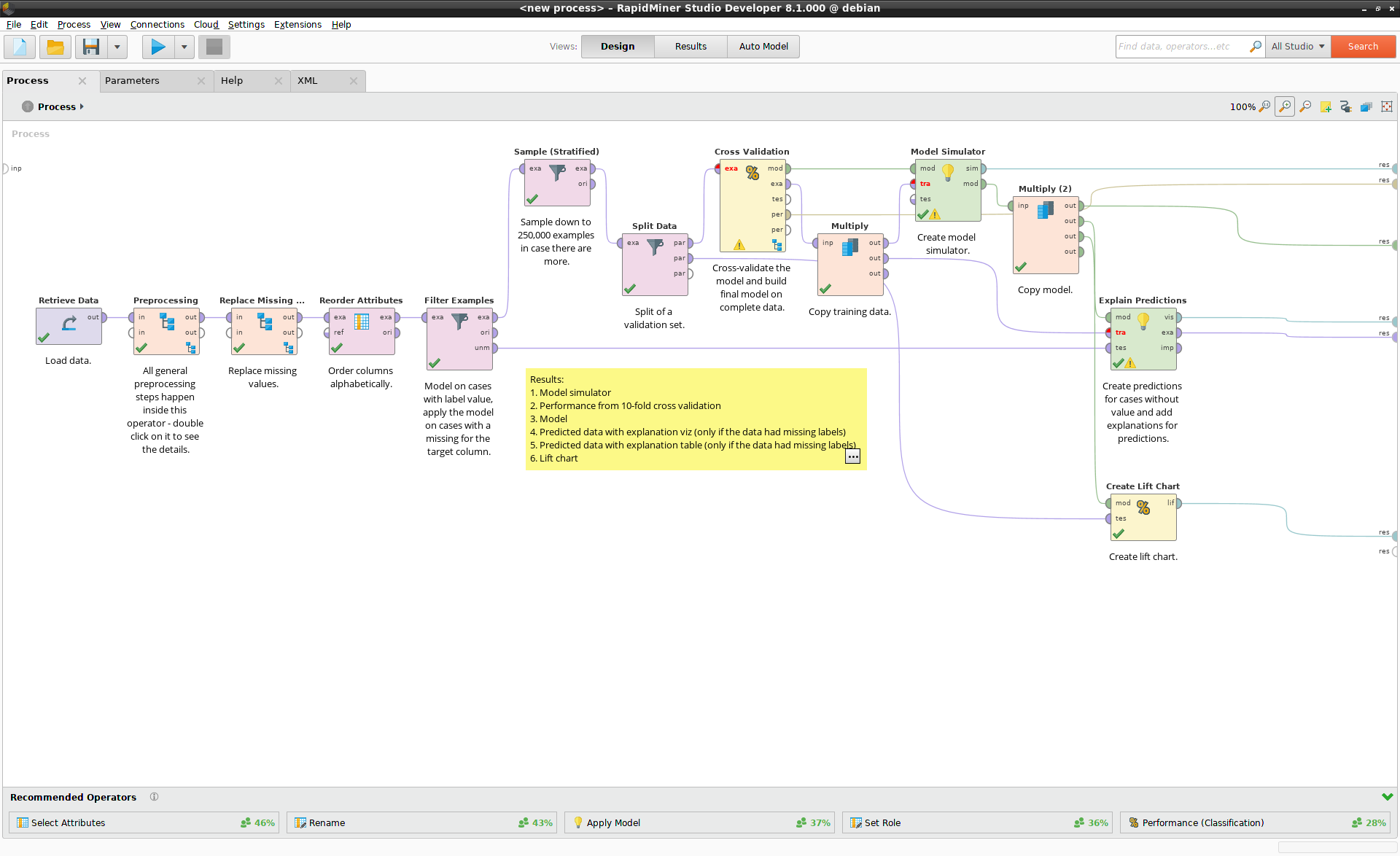
The screenshot below shows a more complex process, generated by Auto Model.
A more complex process
Repository
Repository: your central data storage entity. It holds connections, data, processes and results, either locally or remotely.
Also known as: folder, workspace, project
When working with RapidMiner Studio, you need a place to save your work. The Repository can be used to store:
- connections
- data
- processes
- results
- arbitrary files (as of RapidMiner Studio 9.7)
Note that as of RapidMiner 9.7, the concept of Repository has several distinct types:
| Legacy Repository | For RapidMiner Studio 9.6 and earlier, this was the standard Repository, with no version control and a limited set of file types. You cannot create a legacy Repository, but you can still use any legacy Repositories you created previously, or migrate them to a new Repository. A remote Repository on RapidMiner AI Hub is still of this type. |
Remote Repository | Each instance of RapidMiner AI Hub had and still has a unique central Repository, with the same characteristics as RapidMiner Studio's legacy Repository: no version control and a limited set of file types. |
| Repository (local) | As of RapidMiner Studio 9.7, a local Repository supports arbitrary file types, but not version control. A Repository of this type has no counterpart on RapidMiner AI Hub. When you double-click a non-RapidMiner file in a Repository, it opens in the standard application for that file type. When you drag a non-RapidMiner file into the Process Panel, an Open File Operator is created. Extensions, such as the Python Scripting extension, may provide additional functionality, so that dragging a Python script into the Process Panel creates an Execute Python Operator. |
| Project | As of RapidMiner Studio 9.7, a Project supports both version control and arbitrary file types. It behaves in the same way as a Repository, but with the addition of version control. As discussed in the Projects documentation for RapidMiner Studio and RapidMiner AI Hub, a Project always has both a local component and a server component, and the two are regularly synchronized. |
Repositories are the natural place to store your connections and processes (File > Save Process);
whether you save your data, results, or other files in a Repository depends on your use case.
To start with, your data probably lives in a file or a database.
RapidMiner Studio provides numerous Operators to help you import your data
e.g., Read Excel
or Read Database.
To launch the Import Data wizard, click on Import Data in the Repository Panel,
or select File > Import Data from the main menu.
Given the data and the process, your results can always be regenerated, but there might be good reasons to store the results in a Repository:
- If the result is a complex model based on a large data set, regenerating it will take time.
- If you are running a process on RapidMiner AI Hub, you will need to store the results (using the
StoreOperator), because RapidMiner AI Hub has no equivalent to the Results View in RapidMiner Studio.
Bundled Repositories
For both new and experienced users, the Repositories bundled with RapidMiner Studio are an invaluable resource. They provide a wide array of sample data sets and sample processes, together with explanatory notes.
- The
Training ResourcesRepository is a large set of data sets and processes designed as a companion to the training lessons and courses at the online RapidMiner Academy. We encourage you to take advantage of these free courses to practice your skills. - The
SamplesRepository contains additional data sets and processes, including Time Series examples underSamples>Time Series. - The
Community SamplesRepository is a special collection of data sets and processes published by our top users in the RapidMiner User Community, not by the RapidMiner team. Each process contains a header naming the author, giving a brief explanation of the purpose, and linking to the thread from which it originated. We encourage users to read the online conversation that accompanies each process before using it, because processes in this Repository do not necessarily run as published.
Operators
Operators: The elements of a Process, each Operator takes input and creates output, depending on the choice of parameters.
Also known as: function, formula, node
To use RapidMiner Studio effectively, you have to learn about its Operators. RapidMiner Studio includes hundreds of Operators, and therefore a large part of the task is learning how to find what you need. As so often with search, there are two major strategies: hierarchical search and keyword search. The RapidMiner Community is also a source of support.
To verify that the Operator you have found has the functionality you expect, read the Help.
Once you've found the Operator you want, there are at least 3 ways of getting it into the Process Panel.
Drag-and-drop the Operator
Double-click the Operator
Right-click the Operator, and choose
Insert Operatorfrom the context menu.
Hierarchical search
The hierarchy of folders in the Operators Panel reflects a typical data science workflow:
- Data Access
- Blending
- Cleansing
- Modeling
- Scoring
- Validation
- Utility
- Extensions
By opening these folders and their subfolders, you will get some insight into what's available.
This same hierarchy can be examined on the docs website, which includes the Help for each Operator.
Keyword search
The alternative is keyword search. Although the Operators Panel includes a search field, the recommended procedure is to use the global search, in the upper right corner of the user interface. The global search finds not just Operators, but data and processes from the Repository, extensions from the Marketplace, and even actions you can take from the menu!
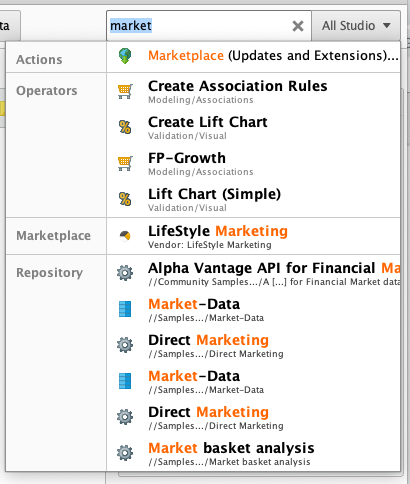
Hint: when you hover an Operator displayed by the global search, the Help for that Operator is displayed immediately in the Help Panel. If you first maximize the Help Panel, you can quickly scan the Help pages for all the Operators that appear in your search.
Community search (Wisdom of Crowds)
If you've started building a process, and you're looking for hints, the "Wisdom of Crowds" can be helpful.
The "Wisdom of Crowds" is an opt-in recommender system, based on the usage pattern of other RapidMiner users.
It predicts which Operators you might need, based on the Operators that are already included in your process.
To activate it, click on the button that says Activate Wisdom of Crowds.
You can activate it or deactivate it at any time via the menu item
Settings > Preferences > Recommender > Enable operator recommendations.

If you still can't find what you are looking for, the RapidMiner Community can probably help. RapidMiner's data science team actively contributes.
Parameters
Parameters: Options for configuring the behavior of an Operator.
The content of the Parameters Panel is context-dependent.
Select any Operator that is displayed in the Process Panel,
and the Parameters Panel displays the options for configuring that Operator.
Because RapidMiner Studio includes many Operators, each with its own
unique functionality, the range of parameters is also quite diverse.
By default, RapidMiner Studio will show you only the more commonly used parameters.
To see all of the available parameters, click Show advanced parameters.
To understand the parameters, you need to learn more about the Operator; reading the Help for that Operator is probably a good place to start. Alternatively, hover the information icon 🛈 next to the parameter of interest, and a help text is displayed.
Help
Help: Displays a help text for the current Operator.
The content of the Help Panel is also context-dependent. Select any Operator that is displayed in the Process Panel, and the Help Panel displays a help text for that Operator. The Help Panel provides useful background information, including:
- An overview of the Operator, its purpose, and its functionality
- A description of the Operator's input and output ports
- A description of the Operator's parameters
- One or more examples, in the form of a Tutorial Process
Within the Help Panel, clicking on an example immediately opens the associated Tutorial Process in RapidMiner Studio, so that you can examine a relevant application.
All of the Operator help texts provided within RapidMiner Studio are also available online.
Reconfiguring the Design View
To restore the Design View to the default panel setup, select View > Restore Default View.
To optimize your screen real estate, you might consider reorganizing the panels. Notice first that you can right-click the tab connected with any panel, and select one of the following:
Detach- The panel is detached from RapidMiner Studio.Maximize- The panel fills the entire space allotted to panels.Close- The panel is removed from the user interface.
If you need more space to read the Help, for example, you can maximize the Help Panel,
then click the panel tab a second time to restore the user interface to its original state.
If you don't really need a panel, you can close it.
A closed panel can be restored via the menu items under View > Show Panel.
Additional configuration is available via drag and drop:
- Panels can be resized
- Panels can be moved
- Panels can be displayed as tabs.
The table below summarizes the available panels, most of which are not displayed,
e.g., the XML Panel, that displays an XML representation of your process.
The panels displayed in bold are the default panels.
To display a panel from this list, select it from the menu under View > Show Panel.
| Panel | Description |
|---|---|
| App Objects | Simulate a RapidMiner AI Hub App environment |
| Background Monitor | Manage background processes and results |
| Context | Advanced process settings and macros |
| Data editor | Offers spreadsheet-like data manipulation |
| Help | Documentation for the selected Operator |
| Log | View recorded events |
| Macros | Live overview of defined macros |
| Operators | All Operators available to add to your process |
| Overview | A zoomed out overview for huge processes |
| Parameters | Configure Operator behavior in your process |
| Problems | View potential problems in your process |
| Process | Create and design your process here |
| Repository | Manage your data and processes |
| Resource Monitor | Displays the RAM currently used |
| Result History | A history of all process results this session |
| AI Hub Monitor | Processes running on RapidMiner AI Hub |
| Snapshot History | Show the Snapshot History and status of Projects under version control |
| Tree | A tree representation of your process |
| XML | An XML representation of your process |
To restore the Design View to the default panel setup, select View > Restore Default View.