You are viewing the RapidMiner Scoring-agent documentation for version 9.9 - Check here for latest version
Create a deployment file
A deployment file defines web services that are exposed by the Scoring Agent to score data. Following section describes step by step how to create and obtain a Scoring Agent deployment file from RapidMiner AI Hub repository and from Projects.
Create a deployable asset
To create a deployment file for the Scoring Agent create a new folder either in the RapidMiner Server repository or in projects. The folder can be placed anywhere and will be used to define the contents of the deployment. Keep in mind that everything stored in this folder will be included in the deployment file. This includes processes as well as data and models. Top-level processes of the deployment folder will be exposed as web services (endpoints).
The image below shows an example deployment folder called score-fraud in the repository. You can also place a similar
structure into a Project:
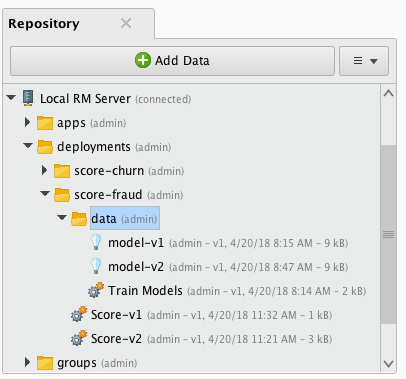
It contains two top-level processes called Score-v1 and Score-v2 and a data/ folder.
The data/ folder contains the production models model-v1 and model-v2 that are used by the top-level processes
for scoring and a training process Train Models which builds the models.
In general the Scoring Agent exposes top-level processes of a scoring folder based on following schema:
http://$SA_HOST/services/$folderName/$processName
Therefore, the base path of the deployment will be the same as the folder name and the endpoint paths of the two
top-level processes will be the same as the process names. Let's assume the Scoring Agent is running on localhost
with default settings. The full URL of the web services exposed by the score-fraud deployment will look like this:
http://localhost:8090/services/score-fraud/score-v1http://localhost:8090/services/score-fraud/score-v2
The process Train Models will not be available as a web service as it is not a top-level process.
Please note that special characters in the name of the deployment folder and top-level processes will be URL encoded.
A process called score customer stored in the folder customer churn/ will be available as a web service at http://$SA_HOST/services/customer%20churn/score%20customer.
Create a scoring process
Each web service offered by the Scoring Agent relies on a RapidMiner Studio process.
Here's an example of a simple scoring process:
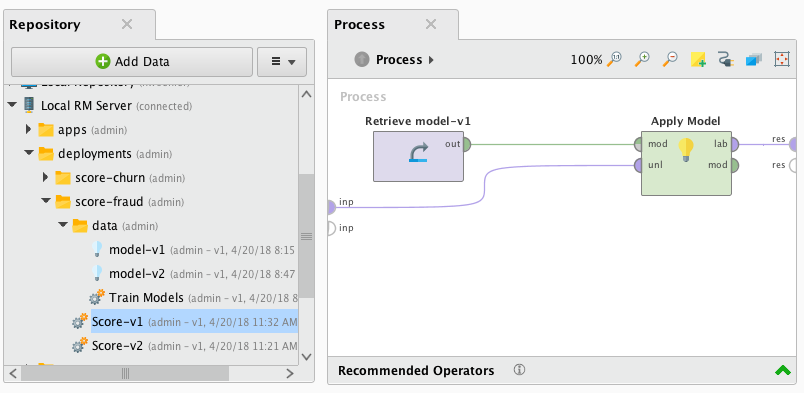
The process will load a previously trained model from the repository and apply it on the input data. Afterwards the scoring results will be delivered to an output port.
The Retrieve operator works only with relative paths and only with data that is contained in the deployment folder or its subfolders.
For easier local testing of a scoring process you can assign input data to the input port via the process context. Or just drag&drop data on the input port.
Execution Mode
By default, the RTSA is designed to be reactive, i.e. the execution of deployments are manually triggered via a REST call. With the continuous mode it is possible that deployments are being executed and restarted after each execution automatically.
The continuous mode can be switched on or off when you download the deployment file.
By default, the execution order of the endpoints in a continuous deployment is automatically set during ZIP creation.
To change the execution order, you will need to edit the config.json within the newly created deployment ZIP file and
adjust the order attribute. The endpoints will be executed in ascending order.
What's next?
Either create a deployment file from the repository or create a deployment file from Projects.