MLFlow tutorial
MLOps is crucial for any end-to-end machine learning project lifecycle. The Altair RapidMiner platform provides a horizontally-scalable workload execution architecture, allowing for highly parallel executions of different tasks and workloads, including training numerous models, and tracking their characteristics and performances as experiments based on the MLFlow extension.
Experiment Tracking: An experiment is the primary organizational structure within MLFlow. It is a collection of runs that allows you to visualize, search for, and compare them. A run is a single execution of your training workflow that can contain performances, metrics, and other parameters.
Model Registry: The model registry in Altair RapidMiner registers and manages models in production, including the storage of diverse model metadata, hyperparameters, workflows, codes, and model instances (for example, a trained decision tree or neural net model).
To use the MLOps functionalities, install the MLFlow extension from the marketplace in Altair AI Studio.
Experiment tracking
Example: Titanic survival prediction experiments
To show how the Altair RapidMiner platform provides the capability of tracking machine learning experiments, we’ll use the Titanic dataset, included with Altair AI Studio, to create experiments in MLFlow, train a decision tree model and log different metrics for each training run.
Create a connection
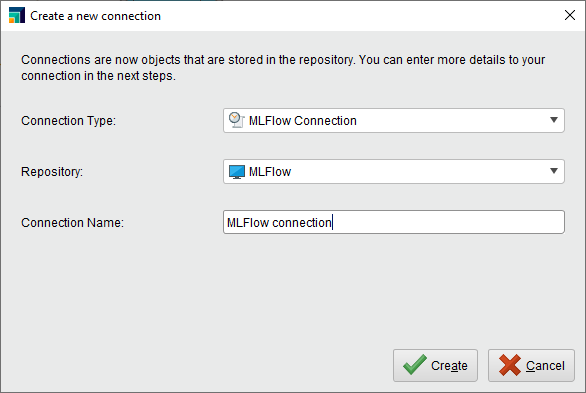
Add a connection to your MLFlow server and save it in your repository. Provide the URL for the MLFlow tracking server. If required, configure the authorization method.
Create an experiment
After setting up the connection, use the operator Create Experiment to create a new experiment on the MLFlow tracking server. Set the parameter's experiment name to Titanic survival prediction and run the workflow. You can now see the experiment created on the MLFlow server.
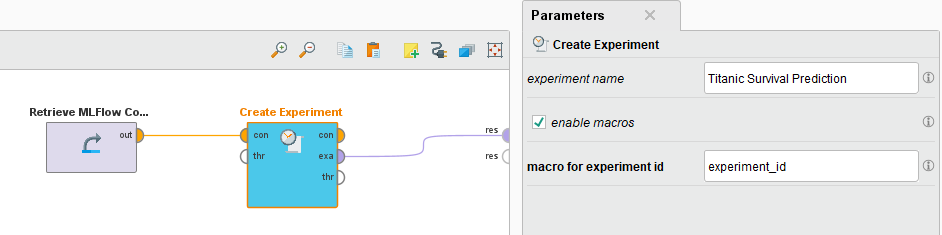
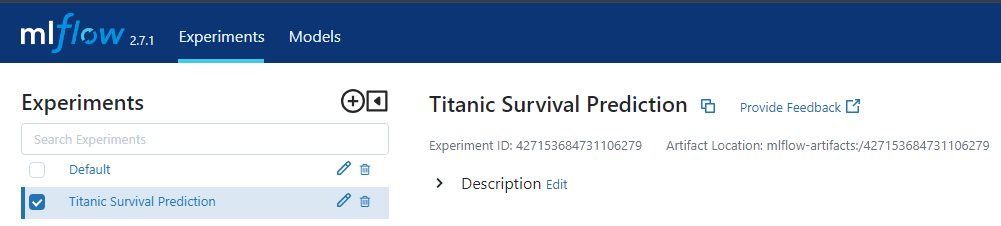
You can note and use the experiment ID during the model training workflows when you use the create run and log Run operators. The operator also allows you to set the experiment ID as a macro.
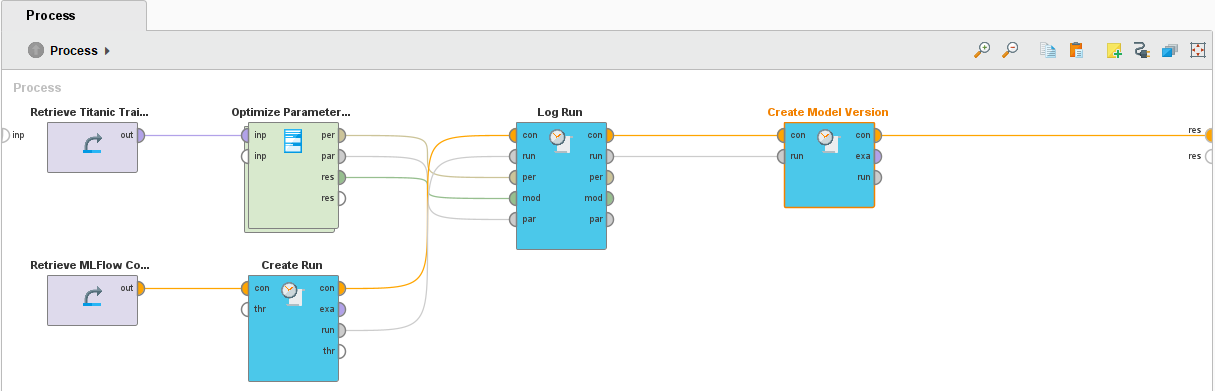
Log the model training run
Having set the experiment, we want to train a decision tree algorithm for each iteration using optimization and log performance metrics. We will create the workflow and use the Create Run and Log run operators from the MLFlow extension. The screenshot below shows the sample workflow where the Optimize Parameters (evolutionary) operator trains a decision tree algorithm. The performance metrics logged are accuracy, absolute error, relative error, and root mean squared error.
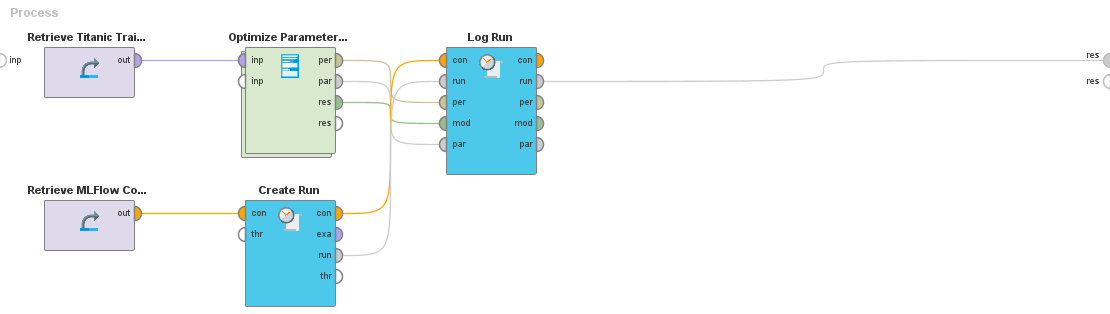
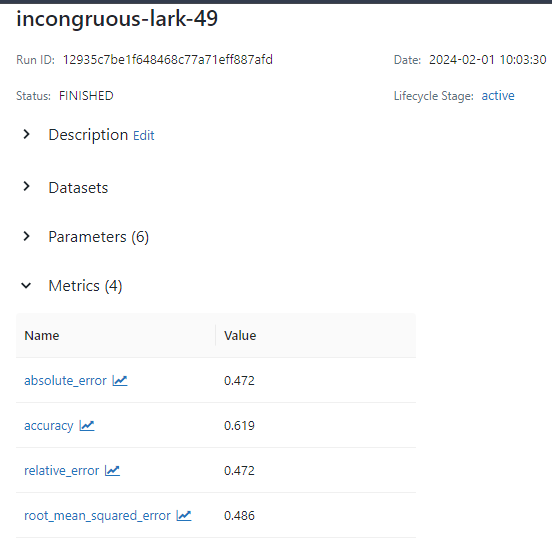
Run the training workflow and view the runs on the MLFlow tracking server. The run includes the logged performance metrics, parameters, and the trained model artifacts.
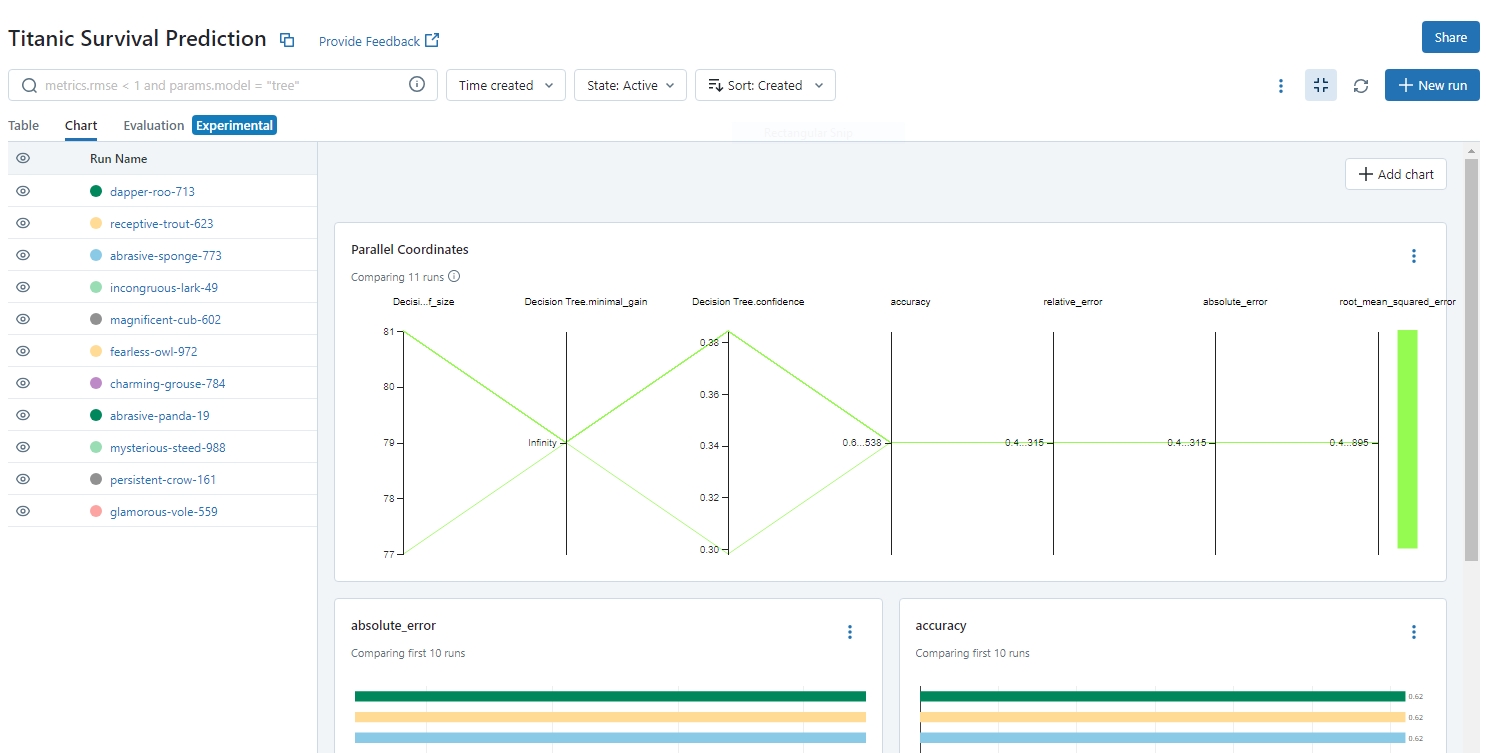
You can also compare the previous runs on the tracking server to analyze the logged metrics and understand the model's behavior.
Model management
The model artifact generated during the training workflows can be registered in the MLFlow Model registry. We can create a workflow to create and register a new model named Titanic Survival.
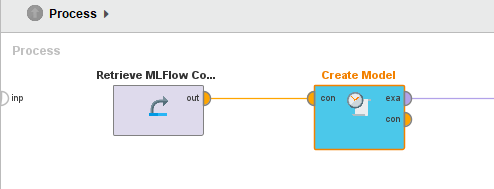
In the workflow created during the training phase, we can add the operator Create Model Version and register a new version of the model with each run.
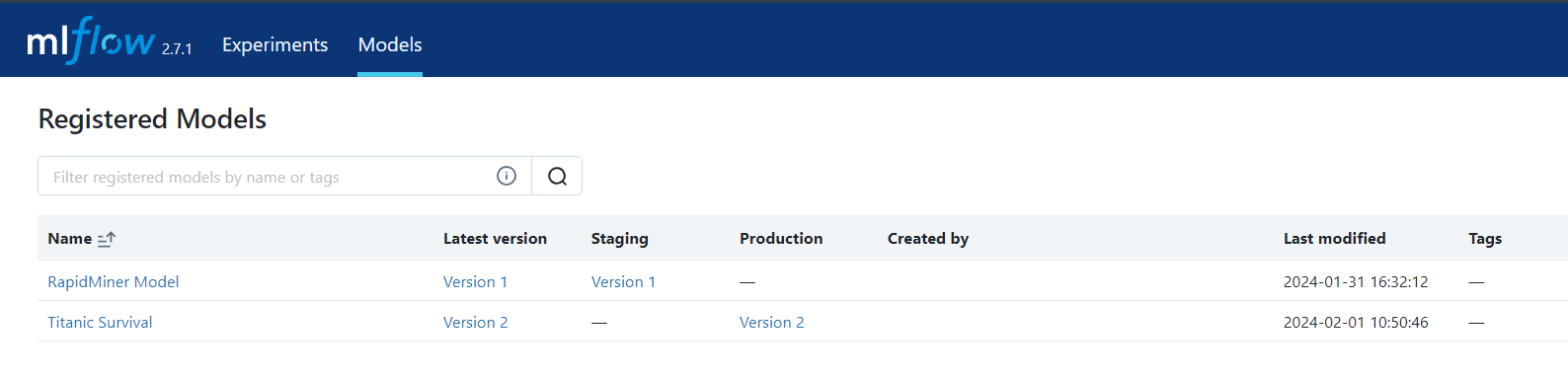
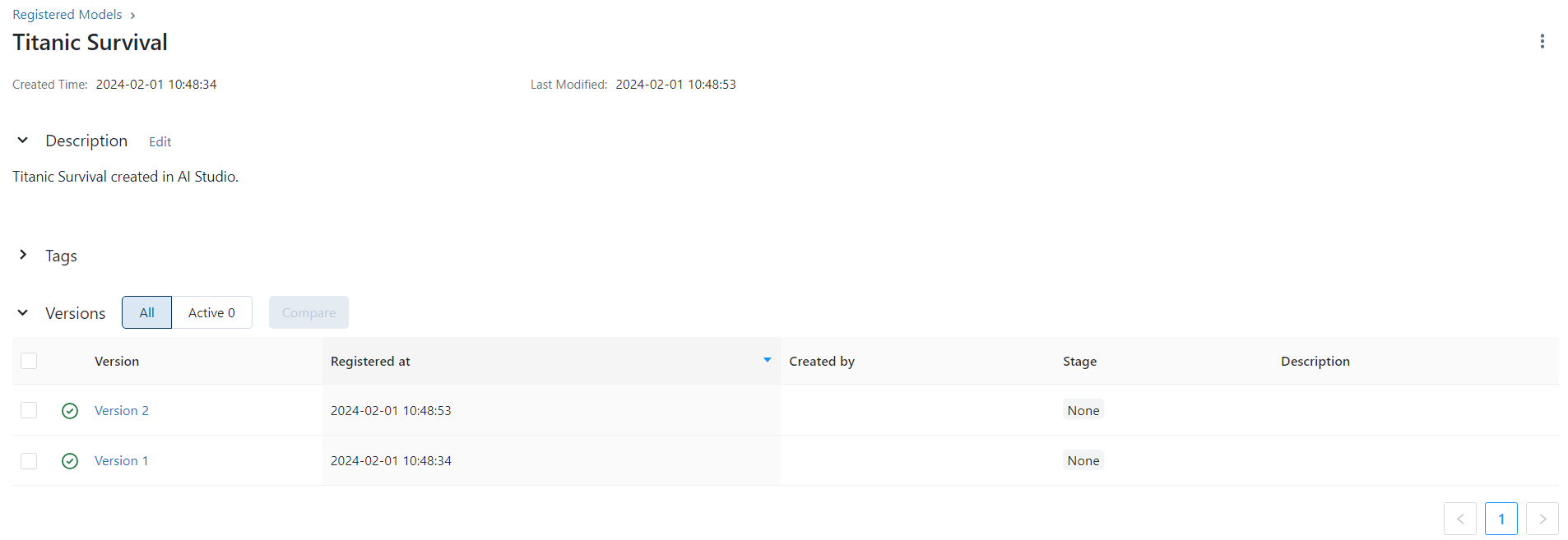
Once the workflow runs, a new version of the model is created. To check the version of the model created on each run, you can check the model registry page on the MLFlow server.
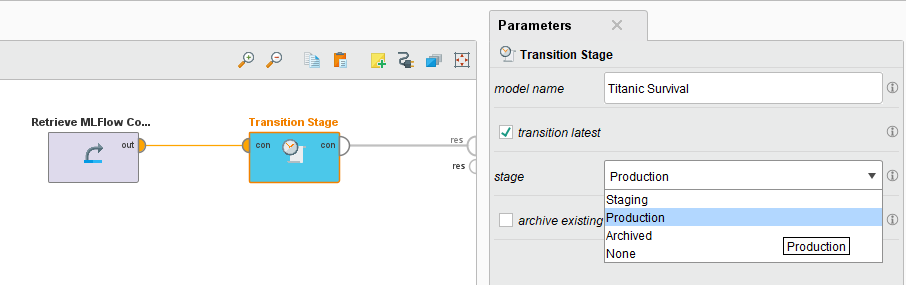
Transitions
Having validated the model in staging, we can move it to production using the transition stage operator. To do so, specify the latest model version from the registry to be moved. You can also select the option of archiving the existing version.
After running, you can verify the latest model version updated to the Production state on the Model Registry page.