You are viewing the RapidMiner Server documentation for version 8.1 - Check here for latest version
RapidMiner Server Overview
RapidMiner Server is a performance-optimized application server where you can schedule and run your analytic processes and quickly return your results. It seamlessly integrates with not only RapidMiner Studio, but other enterprise data sources as well, allowing processes to continually update so that they reflect any changes to external data sources. With shared repositories and version management, contributors throughout your organization can — locally or remotely — collaborate, build interactive apps, and visualize results using HTML5 charts and maps.
Understanding the general infrastructure
There are several main components to a RapidMiner Server configuration:
| Component | Description |
|---|---|
| RapidMiner Studio | RapidMiner Studio is where you build and edit analytic processes. RapidMiner Studio and RapidMiner Server connect and interact with each other, employing standard protocols. For each instance of RapidMiner Server, you can connect one or multiple RapidMiner Studio clients. |
| RapidMiner Server | Although a separate application and license, RapidMiner Server requires RapidMiner Studio for operations. While you can run a process from RapidMiner Server, if you want to edit or change a process, you must make those changes through RapidMiner Studio. |
| RapidMiner Job Agent | Job Agents are responsible to orchestrate execution on a node they are deployed. After an agent is running and connected to a queue it will start Job Containers whenever a process is available on the queue. |
| RapidMiner Job Container | Job Containers are responsible to execute a process. Their lifecycle is managed by the Job Agent which started them. |
| RapidMiner Server repository | Also accessible from RapidMiner Studio, the RapidMiner Server repository contains the RapidMiner Server processes and data. |
| Data sources | The individual user data sources, for example, those used for model building. Connections allow you to connect to databases or to connect to other data sources. Best practice suggests that you configure both RapidMiner Server and RapidMiner Studio with access to the data source. Connections to the data sources are used when building processes with operators such as Read Database or Write Amazon S3. |
| Operations database | The RapidMiner Server database (schema) stores configuration files, cron job details, user report requests, and other internal RapidMiner data. You can use an existing database server or create a new one; it can reside locally or on a remote host. (The installation instructions provide an example of creating a MySQL database schema.) |
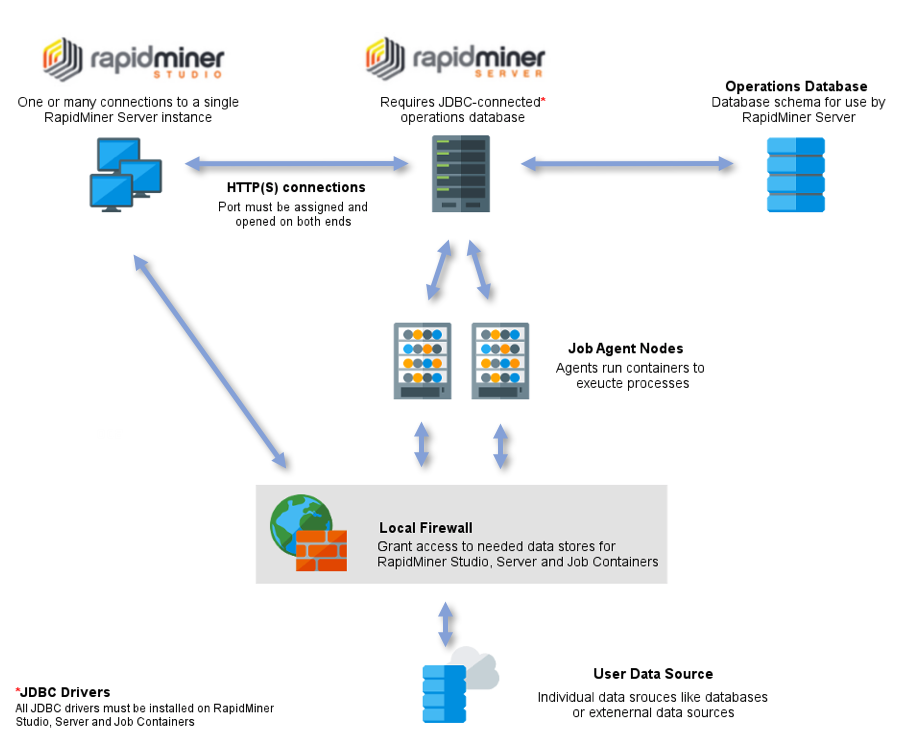
RapidMiner Studio and RapidMiner Server communicate via HTTP(S); you must assign and open the communication port on each instance in the configuration. Although true for any configuration, in the case of multiple clients, access rights management is particularly important for preventing unauthorized user access to repositories.
RapidMiner Server and Job Agents
RapidMiner Server outsources execution (excluding executions triggered via Web Services) to an external entity called Job Agent. It does so by creating asynchronous queues to which it allows these agents to connect to.
Agents receive process messages via these queues and send back information about their own status, the status of the processes they are executing and process logs if requested. A Job Container
is spawned before each process execution, these containers run in their own JVM as a standalone OS process. The JVM terminates once the process has finished executing. To learn more about Job Agents, you can read the page
Installation > Job Agents, or read the README.md file inside the agent distribution.
Job Agents do not pick up existing executions in case they go down unexpectedly and boot up again. These executions have to be terminated manually by the administrator.
Using the RapidMiner Server repository
The RapidMiner Server repository, as with the local RapidMiner Studio repository, contains processes and data. Some details:
When you open the
 RapidMiner Server repository in the Repository view of RapidMiner Studio, the platforms collaborate, making the data and process available to both applications.
RapidMiner Server repository in the Repository view of RapidMiner Studio, the platforms collaborate, making the data and process available to both applications.You create processes in RapidMiner Studio and then save them to the
RapidMiner Server repository. They are available from both platforms.Those processes reference data sources, which can exist directly in the RapidMiner Server repository, or can be referenced by connections that are used in operators.
Use the RapidMiner Server repository in the same way as you use the RapidMiner Studio local repository, although additionally, with correct permissions, users can share content.
Connecting to data sources
You can define connections on RapidMiner Server and assign appropriate access rights instead of individually configuring those connections for each user. RapidMiner Studio downloads all database and other connections available to the local user upon opening the ![]() RapidMiner Server repository.
RapidMiner Server repository.
RapidMiner Studio accesses a data source directly and must have access to the data through any local firewalls. RapidMiner Server may access the data source directly or through RapidMiner Studio and also needs firewall access.
Both RapidMiner Studio and RapidMiner Server need to have any JDBC drivers that you use for a database connection. If you are using a driver that is not packaged with RapidMiner software, install it on both platforms.
See the section on creating connections for complete details.
Connecting to the operations database
See the installation instructions for details of setting up the operations database. Be aware, however, that the operations database also requires a JDBC driver, which you configure during the installation process. Make certain that if you are using a driver that was not packaged with the RapidMiner software that you also install the driver on RapidMiner Studio.