You are viewing the RapidMiner Studio documentation for version 9.6 - Check here for latest version
Using the RapidMiner Studio Built-in Samples
When you have completed the tutorials, you can use RapidMiner Studio's built-in samples repository, with explanatory help text, for more practice exercises. The sample data and processes are located in the Repository panel:
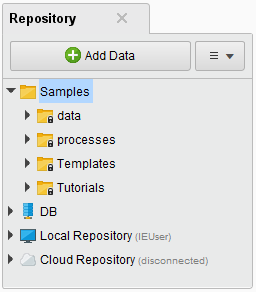
- The data folder contains a dozen different data sets, which are used by the sample exercises. They contain a variety of different data types.
- The processes folder contains over 130 sample processes, organized by function, that demonstrate preprocessing, visualization, clustering, and many other topics.
To use the samples, expand the processes folder.
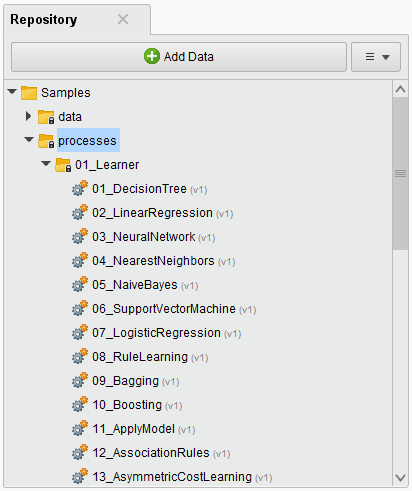
There are two mechanisms for using these processes:
- double-click to display the individual operators with help text. This method is best for learning.
- drag-and-drop to have the process immediately available for running.
Double-click for additional detail
You can learn a lot by double-clicking a sample process.
Select a process. This example uses 01_DecisionTree.
Double-click on the process name. RapidMiner opens the process and displays it on the canvas:
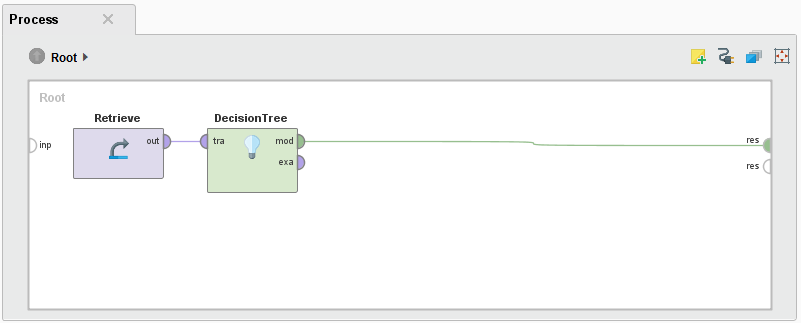
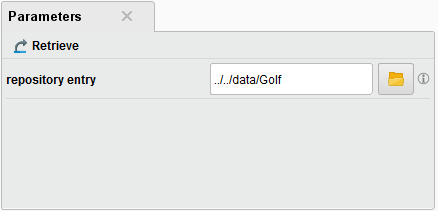
To see the parameters set for an operator, click on it. For example, if you click on the Retrieve operator, the Parameters panel reports the data set in use ("Golf"):
Click
 to run the process.
to run the process.
Drag-and-drop for efficiency
If you drag a process from the repository onto the canvas, things look different than they did above. RapidMiner automatically creates an Execute operator, which, when run ![]() , executes the process you dragged in.
, executes the process you dragged in.
Again, this example uses 01_DecisionTree.
Drag 01_DecisionTree onto the canvas.
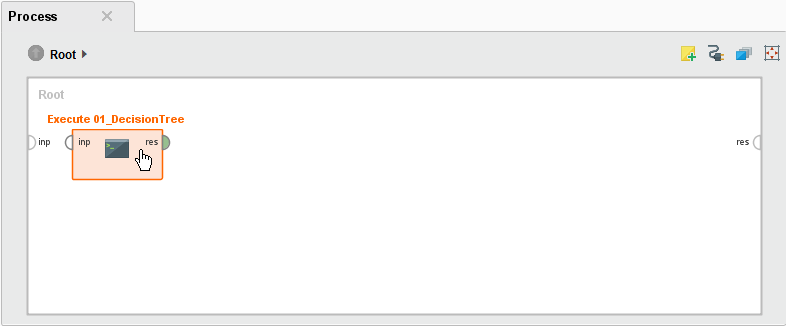
Notice that what you see is the Execute operator. You cannot see the operators that make up the process. For that, you would need to double-click the process in the Repository panel.
Connect the results (res) port of the Execute operator to the results port of the process and click run
to run the process.
As you gain experience and begin to design complicated processes with multitudes of operators, you will want to build in some structure. By saving multi-operator processes, you can reuse them as needed. For example, if you do a lot of analysis, you can make one process for updating data, one for data preprocessing, one for model creation, one for model performance checks, etc. Save each process to the repository and drag them to the canvas as needed. Then, your main process will contain just interconnected Execute operators. Neat and tidy.