Using the Streaming extension
The Streaming extension allows to build streaming analytic processes and deploy them on an Apache Flink or Spark streaming cluster. The design follows the known operator based approach inside a special nested operator called Streaming Nest.
The data flow works with Apache Kafka topics as data source and sink for the streaming process. To see how to establish Kafka connections see the entry for the Kafka Connector extension.
- Install the Streaming extension
- Connect to a Streaming Cluster
- Building a Streaming Process
- Monitoring Processes
- Apply Altair AI Studio Models on Streams
Install the Streaming extension
To install the extension, go to the Extensions menu, open the ![]() Marketplace (Updates and Extensions), and search for Streaming Extension. For more detail, see Adding extensions.
Marketplace (Updates and Extensions), and search for Streaming Extension. For more detail, see Adding extensions.
Connect to a Streaming Cluster
The extension requires a connection to a streaming cluster, where the process can be deployed. The processes are technology independent, so the same process can be executed either on a Flink or Spark cluster without changing anything, except the connection object.
Connect to Flink
To create a working Flink Connection object in the repository, the necessary properties must be added. These are the host and port information, the applied parallelism level and the address of the remote dashboard.
Connect to Spark
To create a working Spark Connection object, the necessary properties must be added. The Spark Settings tab handles the basic connection and requires the host address and port number and the link to the remote dashboard.
The Spark Properties tab and the HDFS tabs can hold specific properties of the cluster and depend on the used spark version and server settings.
The HDFS Settings tab takes optionally the URL and path to the HDFS file system.
Building a Streaming Process
The starting point for any streaming process is the Streaming Nest operator. Inside this process, the streaming process is configured and its content is then deployed on a streaming cluster, which is defined via the connection input port.
Inside the streaming nest, only operators from the Streaming extension will be translated into Flink or Spark operations and deployed on the streaming server. Other operators like Multiply can help to organize the workflow. Kafka Connection objects point to the input and output data streams and Altair AI Studio models can be used in combination with the Apply Model on Streams (see below).
Build an ETL Process
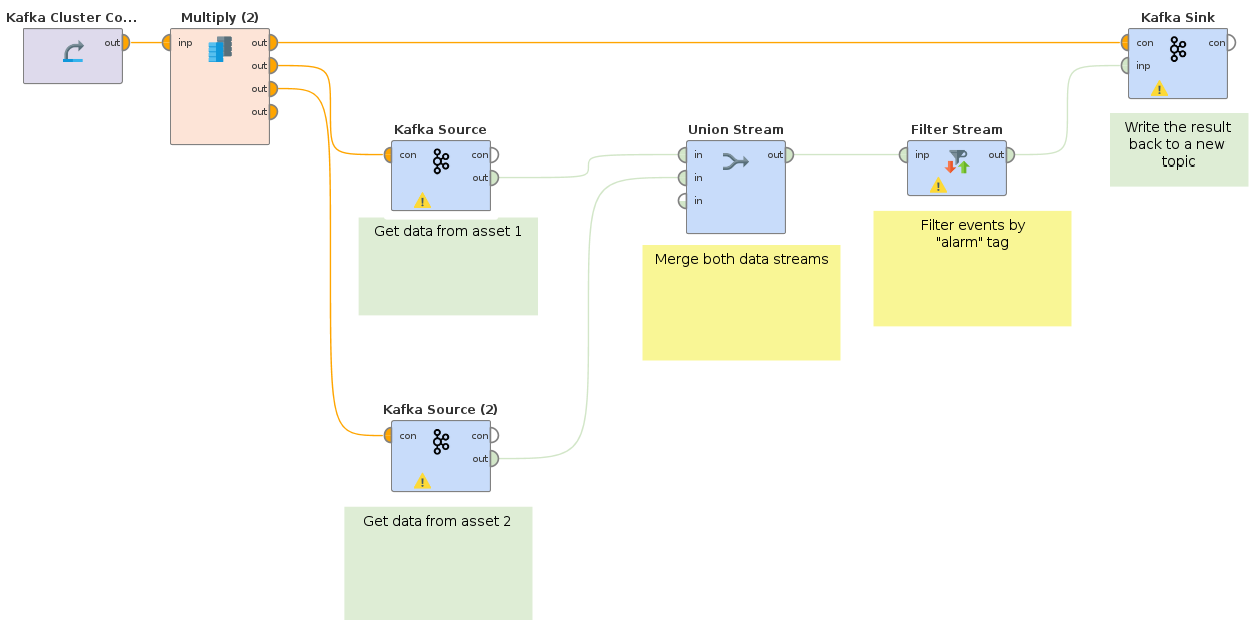
This process merges two incoming data streams from two separate Kafka topics and then filters for a specific key in the data. The results are then written back to a new Kafka topic, where they can for example be used for training a model.
Example use cases:
- The two incoming Kafka streams are events from two separate production plant monitoring services. From the millions of incoming events, only those tagged as "warning" are important for an early warning system.
- The streams could also be click events from two web-shop sites and only events with the key "cancel" should be analyzed, for example to trigger a retention event.
The process below shows how two data streams from different assets are first merged together by a Union operator. The resulting stream is filtered to contain only events with the "warning" tag. The filtered result is written back to a new Kafka topic.
Apply Model on Streams
Based on the example above, the second example shows how to train and apply any Altair AI Studio model on a streaming cluster.
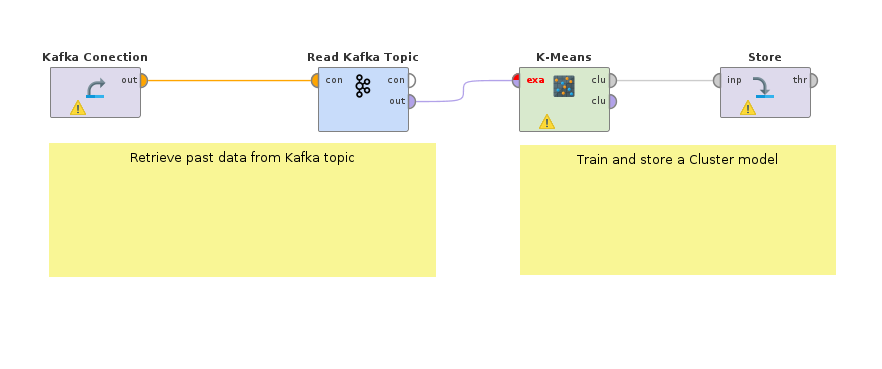
The first step is to retrieve the data and train a model on historic data. For example, the Read Kafka operator from the Kafka Connector extension can be used to retrieve past events with a "warning" tag from the plant monitoring. A k-Means clustering model can detect sub-groups of alarms, that help to automatically distinguish between different types of problems. If there are labeled data available, a supervised learning model could also be trained; for example a model to predict the severity level of an alarm.
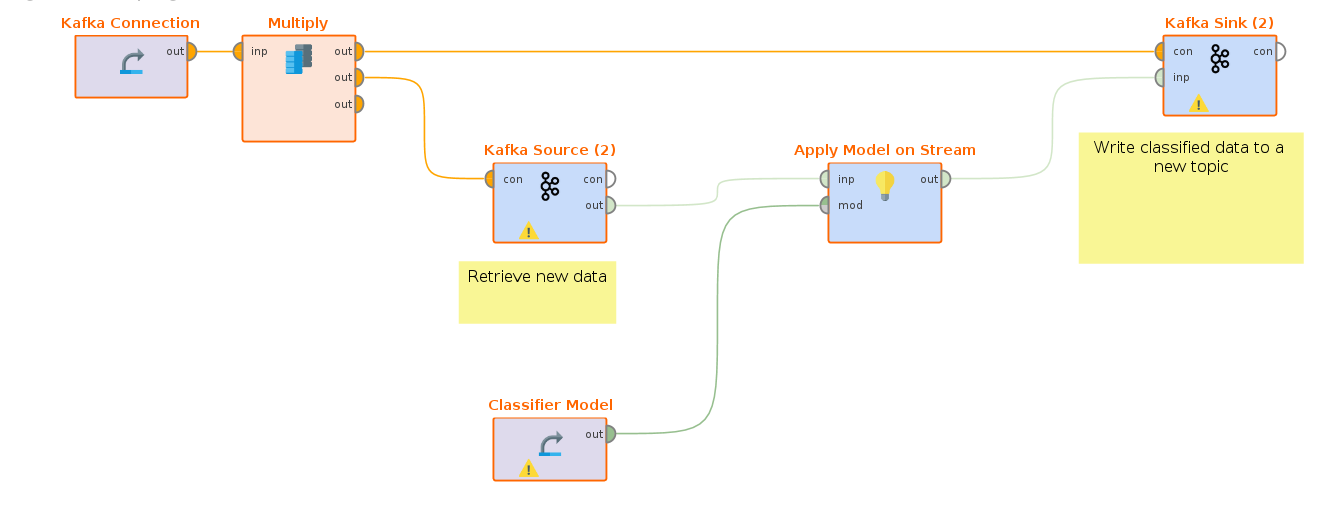
Now the trained model is placed in inside a Streaming workflow. This model is then applied on the filtered alarm events stream and the results with a prediction are pushed to yet another topic.
Monitoring Processes
The Streaming extension adds a new panel to Altair AI Studio, the “Streaming Dashboard”. It can be added to the User Interface under View -> Show Panel -> Streaming Dashboard.
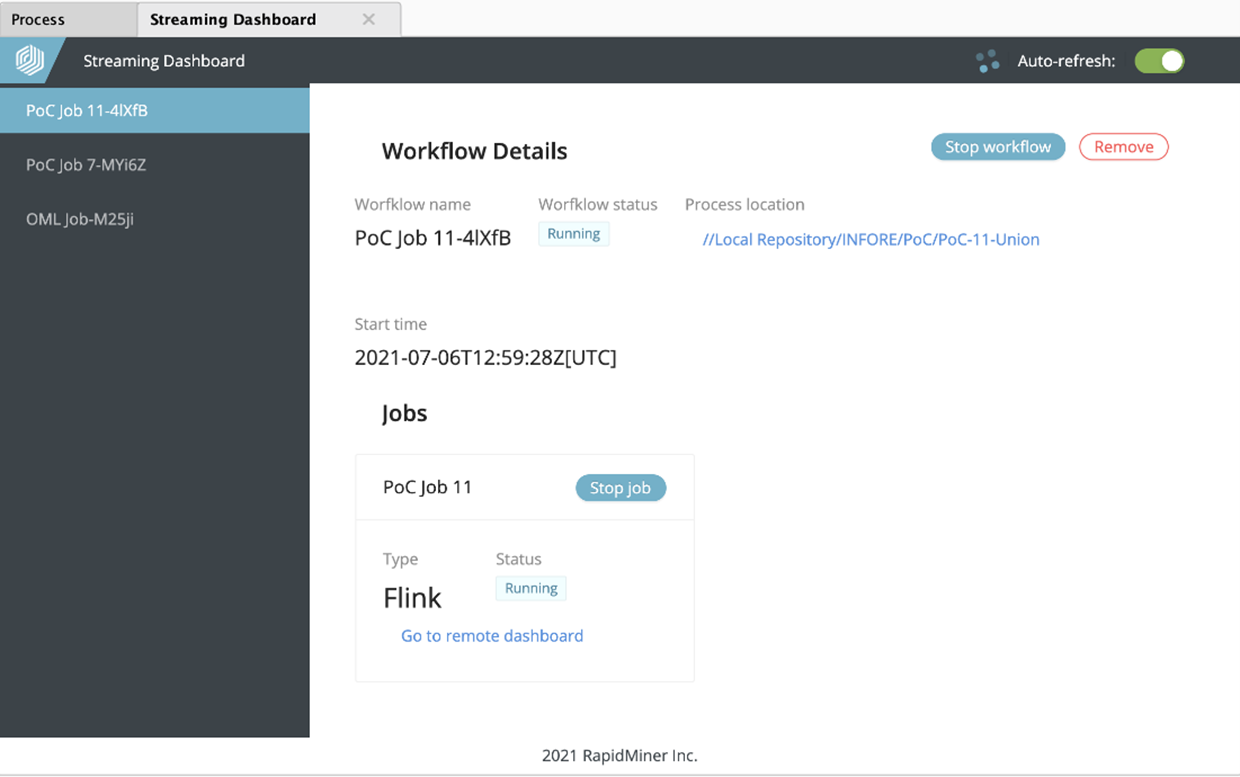
It lists all deployed streaming processes and allows to monitor and manage them. The execution of a Streaming Nest operator creates an entry in the Streaming Dashboard (called workflow). The name of the workflow, the status, the location of the defining process and the start time are listed on the dashboard.
Also all deployed streaming jobs are listed as well. Individual jobs, as well as the whole workflow can be stopped through the dashboard. The entry of the workflow can be removed from the dashboard by using the corresponding button.
The Streaming Dashboard also allows to open the platform specific (Flink or Spark) remote dashboard.
Apply Altair AI Studio Models on Streams
In order to use the Apply Model on Stream operator, some changes to the streaming cluster are needed. The streaming engine (Flink or Spark) needs an extra plug-in so it knows how to handle Altair AI Studio models and of course the Altair AI Studio execution engine is needed to actually run the models.
Install Altair AI Studio on the Cluster
The installation guide for Altair AI Studio can be found here. If special models are used, the extension *.jar file is needed as well and needs to be placed in the .RapidMiner/extensions folder on the cluster. The extension files can be downloaded from the marketplace or copied from the .RapidMiner of the local installation.
Install Plug-Ins
The plug-in file is shipped with the extension and can be found in the Home folder under this path .RapidMiner/extensions/workspace/rmx_streaming after the Streaming extension is installed from the marketplace.
There are two files in this folder called rapidminer-as-plugin-common.jar and rapidminer-as-plugin.jar, with the version number of the extension at the end.
Place the rapidminer-as-plugin-common.jar file into the /lib folder of your cluster installation (for example /opt/flink/lib/).
Preparing the rapidminer-as-plugin-common.jar requires a few more steps: - Create an empty lib folder. - Copy into this folder the content of the lib folder from the fresh installation (without the jdbc and plugins subfolders). - Copy the rapidminer-as-plugin.jar in this folder as well. - Create a plugin.properties file and write the following into it:
plugin.class=com.rapidminer.extension.streaming.raap.wrapper.RapidMinerPlugIn
plugin.id=rm-as-plugin
plugin.version=9.9.0
plugin.description=RapidMiner as Plugin
plugin.license=Apache Licents 2.0
Create a zip-archive with the lib folder and the plugin.properties inside and name it rm-as-plugin.zip (make sure the name is correct, as the code will look for exactly this file).
This zip file then placed in a new folder %RM_INSTALLATION%/lib/rm-as-plugin the installation (so it's a subfolder from where the .jar files where copied from).
Afterwards the cluster instance should be restarted, so that Flink or Spark can load the new plugin.
Executing an Altair AI Studio Model
Now the Apply Model on Stream operator can be used. The two required parameters are the locations of the installation folder (where the rm-as-plugin) was installed and the Home folder, where the extension and user data are stored.
On a typical linux cluster the paths would be something like /opt/rapidminer-9-9-0 and /home/$UserName/.RapidMiner.