You are viewing the RapidMiner Radoop documentation for version 9.2 - Check here for latest version
RapidMiner Radoop Operators
This section provides an overview of the Radoop operator group. For a complete list of these operators, see RapidMiner Radoop Operator Reference (PDF).
When you install the RapidMiner Radoop extension, several new operators become available in the Radoop operator group of RapidMiner Studio:
To help understand where to look for certain functions and the different types of operators available, this section provides an overview of each operator group. For full operator descriptions, see the help text within RapidMiner Studio.
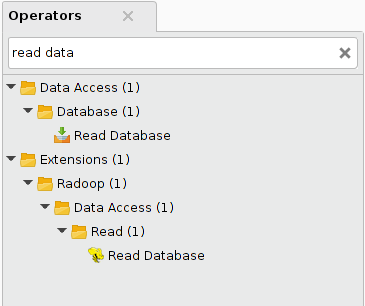
All operators mentioned here are part of the Radoop operator group inside the Extensions group. An operator by the same name may exist as part of the standard RapidMiner operators. The Radoop operator is listed in the Radoop folder and also indicated by a different icon, (such as ![]() ). Searching on Read Database for example, returns these results:
). Searching on Read Database for example, returns these results:
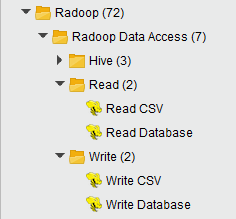
Data Access group
The following operators are part of the Data Access group:
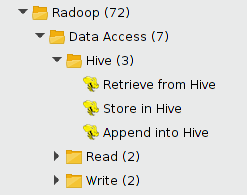
Hive subgroup
The following operators are part of the Hive subgroup:
Note: They are referred to in shorthand below for easier reading.
A process accesses data that already resides on the cluster in a Hive table using the Retrieve operator. Retrieve only loads references and metadata into memory; the data remains on the cluster to be processed with further operators. Connect the output port of Retrieve directly to the Radoop Nest output to fetch the data sample from memory.
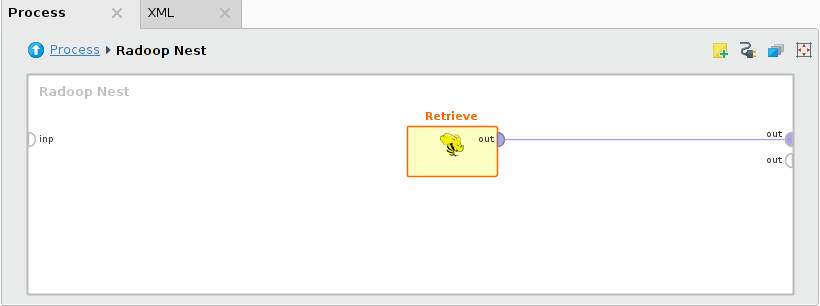
The Store and Append operators write the data on their input ports into a Hive table. Typically this is time consuming, as the cluster has to carry out all the tasks defined by previous data processing operators before writing the data to the HDFS. Append verifies that the data on its input fits into the specified Hive table.
You can also select tables from arbitrary other Hive databases in all operators in this subgroup.
Read subgroup
Data must reside on the cluster to be processed and analyzed by Radoop operators. Smaller data sets may fit into memory; when you connect an ExampleSet to one of the Radoop Nest input ports, Radoop imports it. For larger data sets, use an operator from the Read group — either Read CSV or Read Database.
Read CSV creates a Hive table from a file that resides on the client, the HDFS, or on Amazon S3. With the help of a wizard, you can define the separator and the name of the attributes (or set to read them from the file), as well as modify the type or set the attribute roles.
Read Database queries arbitrary data from a database and writes the results to the cluster. The database must be accessible from the client, which writes the data to the HDFS (using only a minimal memory footprint on the client). Radoop supports MySQL, PostgreSQL, Sybase, Oracle, HISQLDB, Ingres, Microsoft SQL Server, or any other database using an ODBC Bridge. If you want to import from a database in a direct or parallel manner (leaving the client out of the route), look for a solution like Sqoop.
Write subgroup
Write operators (Write CSV and Write Database) write the data referenced by the HadoopExampleSet on their input to a flat file on the client. Alternatively, they can write the data into a database through the specified database connection. The Store operator can be used to write the data to the HDFS or to S3.
This guide contains more detailed information on data import operators in a later section.
Blending group
This is the largest group of Radoop operators; it contains all blending operators organized into subgroups. The operators usually take a HadoopExampleSet as input, and have two output ports — one for the transformed HadoopExampleSet and one for the original. While designing, hover over the first output port to examine the structure or metadata after the transformation.
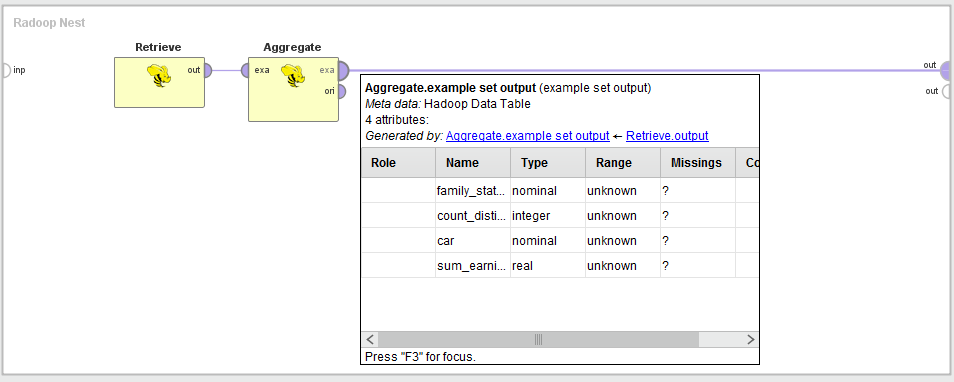
The following subgroups and operators are part of the Blending group:
![]()
There are two standard transformation operators that can take multiple inputs. For combining multiple data sets (HadoopExampleSet objects) use Join or Union operators from the Set Operations group. Join implements the four types of join operations common in relational databases — inner, left, right, or full outer — and has two input ports and one output port. Union takes an arbitrary number of input data sets that have the same structure. The output data set is the union of these input data sets (duplicates are not removed).
Custom transformations can be implemented using one of the scripting operators in Radoop. They can be found in the Utility/Scripting group.
Cleansing group
This group contains operators that perform data cleansing. Like in the Blending group, these operators also receive a HadoopExampleSet as input and have the transformed and original HadoopExampleSet outputs. You can manage the missing values of the input dataset by using the Replace Missing Values or the Declare Missing Values operator and get rid of duplicate examples with the Remove Duplicates operator.
Normalize and Principal Component Analysis have a preprocessing model output. It can be used to perform the same preprocessing step on another dataset (with the same schema). To do this, use the Apply Model operator in the Scoring group.
Modeling group
Besides ETL operators, Radoop also contains operators for predictive analytics. All the modeling algorithms in this group use either the MapReduce paradigm or Spark to take full advantage of the parallelism of a distributed system. They are ready to scale with the large volume of data on your cluster. This section only lists the operators; see the section on Radoop's predictive analytics features for further explanation.
The operators in this group deal with the same type of model objects as core RapidMiner operators do. Thus, model output of a Radoop operator can be connected to the input port of a core RapidMiner operator and vice versa. Models trained on the cluster can be visualized in the same way as models trained on a data set in operative memory. The same compatibility is true for performance vector objects that hold performance criteria values calculated to review and compare model performance. These objects can also be easily shared between operators that operate on the cluster and those that use operative memory.
The following operators are part of the Modeling group:
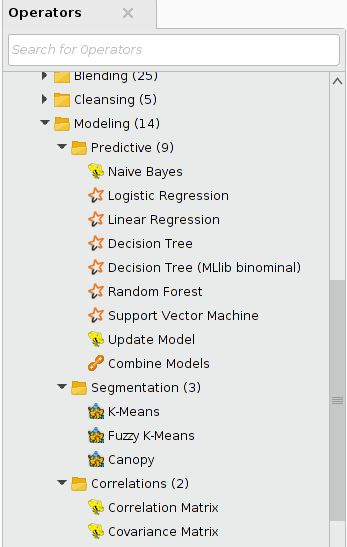
Predictive subgroup
Most operators in this group implement distributed machine learning algorithms for classification or regression. Their prediction model is built on the input HadoopExampleSet on the cluster. The model can be applied both to data on the cluster (see the Scoring operator group) or to data in operative memory by the Apply Model core RapidMiner operator.
Update Model implements incremental learning (for Naive Bayes models only). Incremental learning means that an existing model is modified — its attributes are updated — based on new data and new observations. As a result, the machine learning algorithm does not have to build a new model on the whole data set, it updates the model by training on new records. The operator's expected inputs are the previously built model and a data set having the same structure as the one that the model was built on.
The Combine Models operator combines the trained prediction models on its input ports into a simple voting model — a Bagging Model.
Segmentation subgroup
The Segmentation group contains three different clustering operators. Each of them expects a HadoopExampleSet object on input and delivers that HadoopExampleSet, modified, on output. The algorithms add a new column that contains the result of the clustering; that is, clusters represented by nominal identifiers (cluster_0, cluster_1, cluster_2, etc.). The values identify the rows that belong to the same cluster.
The input data must have an ID attribute that uniquely identifies the rows. The attribute must have the "ID" role (use the Set Role operator). If there is no ID column on the data set, you can use the Radoop's Generate ID operator to create one.
Correlations subgroup
The Correlation Matrix and Covariance Matrix operators calculate correlation and covariance between attributes in the input data set. Correlation shows how strongly pairs of attributes are related. Covariance measures the degree to which two attributes change together.
Scoring group
The Scoring group contains the Apply Model operator. It applies a model to the data on its input port and supports all RapidMiner prediction models. You can train the model from a RapidMiner modeling operator on an ExampleSet in memory or on a Radoop operator on the Hadoop cluster. The operator can apply both prediction and clustering models.
Validation group
The following operators are part of the Validation group:

The Performance (Binominal Classification), Performance (Classification), and Performance (Regression) operators each require a HadoopExampleSet object, having both label and predicted label attributes, as input. Each operator compares these results and calculates performance. You can select performance criteria using the operator's parameters. The generated performance vector object that contains these values is fully compatible with the I/O objects used by core RapidMiner operators.
The Split Validation operator randomly splits an ExampleSet into a training and test set so that the model can then use one of the performance operators for evaluation.
Utility group
This group contains many powerful operators, some of them need some experience with RapidMiner Radoop to use. The following operators are in the Utility group:
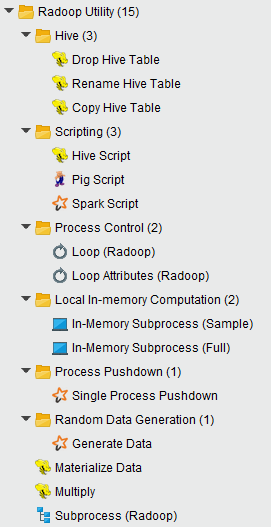
The Subprocess operator lets you run a process inside a process. This operator is a great help in designing clear and modular processes. The Multiply operator is required if you want to use the same HadoopExampleSet object in different branches of a process. The operator simply delivers the object on its input port to every connected output port.
The Materialize Data operator performs all deferred calculations on the input data set and writes the data to the distributed file system (into a temporal table). The Multiply operator simply multiplies the selected input objects.
Hive subgroup
In this group the 3 table management operators do typical management operations on Hive tables. For example, you can use Drop before an Append operator in a loop to make sure that a new process run starts with a new table. Both Rename and Copy can help in more complex processes (for example, that include loops) or they can manage tables of other processes that run before or after them. These tables to be manipulated can be from any Hive database that the user has access to.
Scripting subgroup
To perform custom transformation on your data, you can use either of the three most popular scripting languages on top of Hadoop: Hive, Pig, and Spark. Hive Script, Pig Script, and Spark Script operators in the Scripting group let you write your own code. All three can take multiple input data sets and Pig Script and Spark Script can deliver multiple output data sets. Hive Script and Pig Script operators determine the metadata during design time, and also check whether the scripts contain syntax errors. The Spark Script operator does not handle metadata on its output and has no checks for syntax errors. Syntax highlighting is available for Spark scripts in Python.
Process Control subgroup
The Process Control subgroup contains operators related to organizing the steps of the process. In the Loop operator subgroup, Loop Attributes iterates through the columns of a data set and performs an arbitrary Radoop subprocess in each iteration. The general Loop operator performs its inner subprocess an arbitrary number of times.
Local In-Memory Computation subgroup
The Local In-Memory Computation subgroup contains operators that help you combine processing in the cluster with processing in memory. In-Memory Subprocess (Sample) fetches a sample from a data set in the cluster to memory and performs its inner subprocess on the sample there. This subprocess can use any of the hundreds of core RapidMiner operators. In-Memory Processing (Full) is similar, but it reads and processes the whole data set by performing iterations similar to the Sample version. That is, it partitions the input data set into n chunks, then runs its in-memory subprocess on each of these chunks in a loop with n iterations. It can append the resulting data sets of these subprocesses to create an output data set on the cluster. See the section on Advanced Process Design for more detail.
Process Pushdown subgroup
This group contains one of the most powerful operators in Rapidminer Radoop, the Single Process Pushdown. This meta-operator can contain any operator from the RapidMiner Community Edition and from most extensions (e.g. Text processing, Weka). The subprocess inside the Single Process Pushdown is pushed to one of the cluster nodes and executed using the node's memory. The result is available on the output as HadoopExampleSet (first output port) or as an in-memory IOObject, like a model or a performance vector (other output ports). More information and further hints on this operator can be found on the Advanced Process Design page.
Random Data Generation subgroup
If you need big data on Hive for testing purposes, use the Generate Data operator in this group. It can generate huge amount of numerical data using the selected target function for calculating the label value.