You are viewing the RapidMiner Server documentation for version 9.5 - Check here for latest version
Scalable architecture
To build a RapidMiner Server environment for your data science team, two components have to be installed:
- RapidMiner Server - the central component
- Job Agents - local or remote, to provide scalability
plus the following helper applications:
- RapidMiner Studio - to design the processes you will run in the RapidMiner Server environment
- A database - to store configuration files, cron job details, user report requests, and other support data
The following optional component can be installed, and it runs independently:
- Real-Time Scoring Agents - provide scalability of low-latency web services
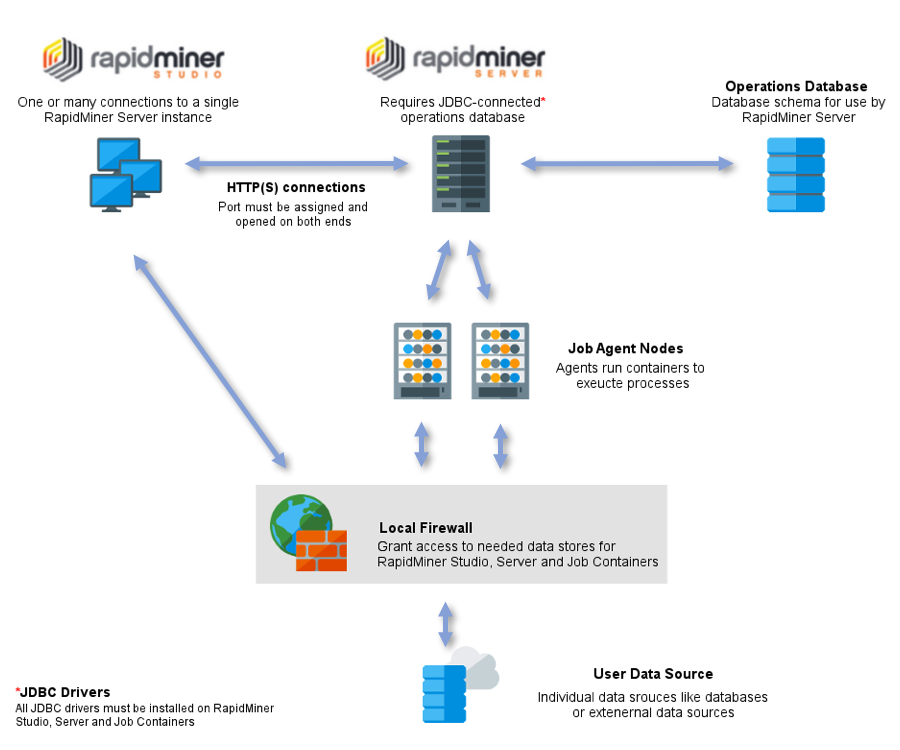
A simple schematic is shown below.
The design
The design of the RapidMiner Server environment reflects a typical data science workflow, where there are two kinds of activities:
Model building, involving long-running processes that can be placed on a queue and run asynchronously
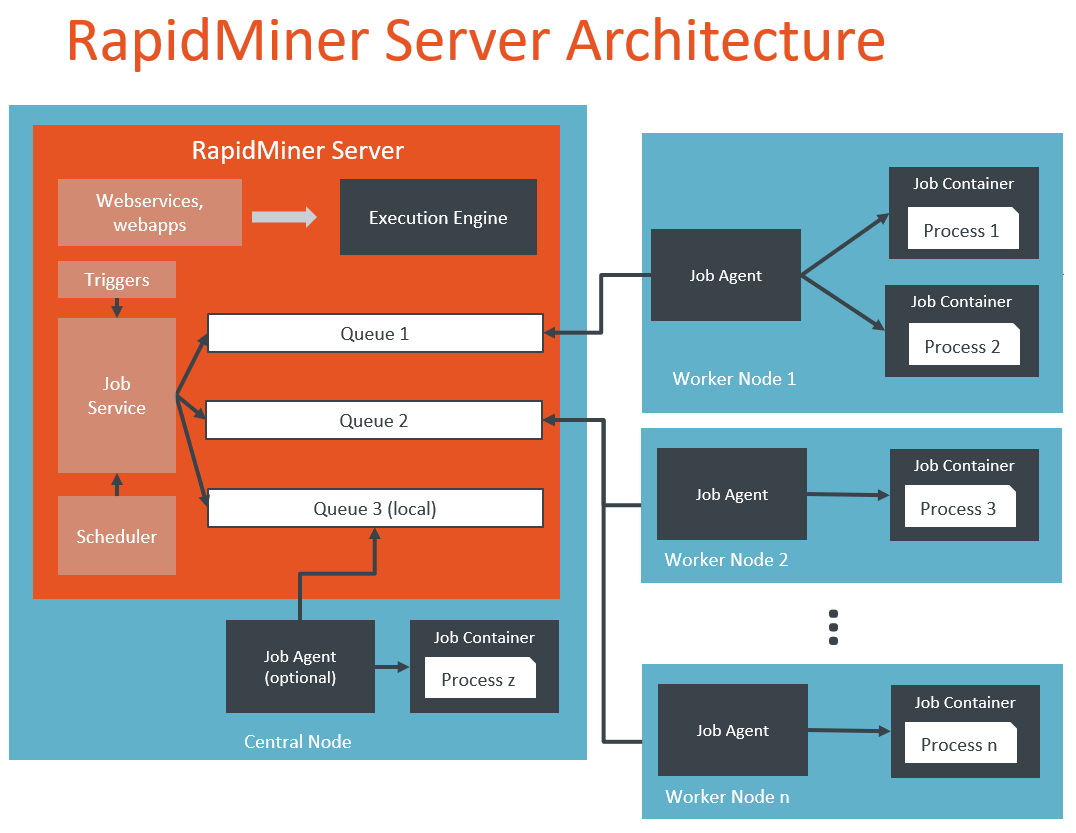
RapidMiner Server offers a queue system for long-running jobs, which are executed externally via Job Agents. You increase processing power by adding Job Agents.
Prediction, or any other application of the models, where the need for a real-time response is paramount
There are two engines for generating predictions:
- Web services, executed directly by RapidMiner Server
- Real-Time Scoring Agents, external entities that run independently of RapidMiner Server
Only the latter are scalable. You increase processing power by adding Real-Time Scoring Agents.
RapidMiner Server
RapidMiner Server is the central component in the architecture. You interact with it via a web interface or via RapidMiner Studio. Its main responsibilities are:
- User, queue, and permissions management
- Scheduling of user jobs (processes)
- Execution of processes called via web services / web apps
- Execution of processes running on the local Job Agent, if it exists
- Repository management (storage of models, processes, etc. and permissions for them)
- Connection management (DB, Hadoop/Radoop, etc.)
Read more: Install RapidMiner Server
In the diagram below, each blue box represents a separate machine. RapidMiner Server is installed on the big blue box on the left, while the blue boxes on the right host remote Job Agents.
Job Agent
The design with Job Agents running remotely on dedicated machines is aimed at scalability. However, one or more Job Agents can be installed locally, on the same machine as RapidMiner Server.
Each Job Agent is configured to point to one of the queues on RapidMiner Server. Its only responsibility is to pick up jobs from the queue and run them. When started, the Job Agent spawns a configurable amount of Job Containers as separate system processes. Jobs are then redirected to those Job Containers and RapidMiner processes are being executed within the spawned Job Containers. When the Job Agent is shut down, all Job Containers of this Job Agent are also shut down. For each Job Agent, the number of Job Containers that can be spawned and the available memory is configurable.
Multiple Job Agents can point to the same queue. You can manage the queues, and therefore the allocation of resources, by assigning permissions.
Read more: Install Job Agents, configure Job Agents, configure Job Containers
Job Container
The Job Container spawned by the Job Agent runs a RapidMiner Studio instance that is capable of executing a RapidMiner process. It's bound to a system port in order to accept jobs from the Job Agent via REST API.
By default, the Job Container will not terminate after each process, therefore providing a nearly instant execution of processes.
It might be desirable to run each job in its own sandbox so that the system is more robust and jobs won't have any effect on previously run jobs. This behavior can also be configured, e.g. to restart the Job Container after a process finished. Please refer to the Job Agent's configuration page for further details.
The price of this safety is latency -- the latency in restarting the Job Container is measured in seconds. Each job will then have this additional latency.
If a real-time response is paramount, we recommend using a web service or a Real-Time Scoring Agent. For example, you might build a model in a Job Container and generate predictions for that model via a Real-Time Scoring Agent.
Real-Time Scoring Agent
As mentioned previously, there are two engines for generating predictions:
- Web services, executed directly by RapidMiner Server
- Real-Time Scoring Agents, external entities that run independently of RapidMiner Server
When generating predictions via the Real-Time Scoring Agent, you need RapidMiner Server to create the deployment, but once it's installed, it runs independently of RapidMiner Server.
As the table below makes clear, the Real-Time Scoring Agent is the scalable, low-latency counterpart to the Job Agent / Job Container. In short, it's just what you need for real-time predictions.
| Component | scalability | low-latency response | instant execution |
|---|---|---|---|
| Job Agent / Job Container | |
|
|
| Real-Time Scoring Agent | |
|
|
| Web service | |
|
|
Read more: Web services
Read more: Real-Time Scoring