You are viewing the RapidMiner Studio documentation for version 9.7 - Check here for latest version
Using the Azure Data Lake Storage Connector
This guide targets the new Connection Management introduced with RapidMiner Studio 9.3.
For the old Legacy Azure Data Lake Storage Connections see the 9.2 documentation
The Azure Data Lake Storage Connector allows you to access your Azure Data Lake Storage Gen1 account directly from RapidMiner Studio. Both read and write operations are supported. You can also read from a set of files in an Azure Data Lake Storage directory, using the ![]() Loop Azure Data Lake Storage operator. This document will walk you through how to:
Loop Azure Data Lake Storage operator. This document will walk you through how to:
Connect to your Azure Data Lake Storage Gen1 account
Before you can use the Azure Data Lake Storage Connector, you have to configure your Azure environment to support remote connections and setup a new Azure Data Lake Storage Gen1 Connection in RapidMiner.
For this purpose, you need to go through the following main steps (see details below).
- Create a web application registration on the Azure portal.
- Acquire information for the remote connection.
- Setup and test the new Azure Data Lake Storage Gen1 Connection in RapidMiner.
Step 1: Create a web application registration on Azure portal
Create and configure an Azure AD web application to allow sevice-to-service authentication with Azure Data Lake Storage Gen1 using Azure Active Directory. Go through Step 1 to Step 3 of the Service-to-service authentication guide. The first step registers a web application that will provide access for RapidMiner to Azure Data Lake Storage. Note that you can use arbitrary values for the Name and Sign-on URL fields. The second step describes how to get your Tenant ID, the application ID for the registered application, and a key that needs to be provided in RapidMiner so that it is able to use this application. The third step configures this Active Directory application to have access to your Data Lake Storage.
After performing those steps in your Azure Tenant, you should have a web application registration that is configured to access some or all folders of your target Azure Data Lake Storage Gen1 resource. Note that for the file browser of the RapidMiner operators (see below) to work, you need to give Read and Execute access on the root directory, and on all directories where you want to allow navigation. Besides that, you need Write permission to be able to write to the cloud storage from RapidMiner. If you can work without the file browser, you can limit the permissions to the target folders / files that your operators directly use.
Step 2: Acquire information for the remote connection
To create the Connection in RapidMiner, you need to acquire the following information. The previous step and linked guide described how to get them, but let's repeat the direct links here to these details.
- Tenant ID that identifies your company's account. Get Tenant ID.
- Fully Qualified Domain Name of your accont. Example: if your Azure Data Lake Storage Gen1 is named
contoso, then the FQDN iscontoso.azuredatalakestore.netby default. - Application ID and application key for the Web application you created. Get application ID and authentication key.
Step 3: Setup and test the new Azure Data Lake Storage Gen1 Connection in RapidMiner
After you have all information, it is straightforward to set up your Connection in RapidMiner.
In RapidMiner Studio, right-click on the repository you want to store your Azure Data Lake Storage Gen1 Connection in and choose
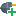 Create Connection.
Create Connection.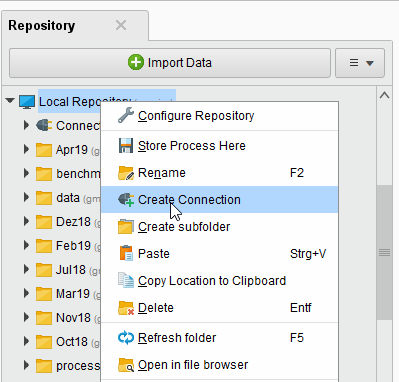
You can also click on Connections > Create Connection
and select the repository from the dropdown of the following dialog.Give a name to the new Connection, and set Connection Type to
 Azure Data Lake Storage Gen1:
Azure Data Lake Storage Gen1: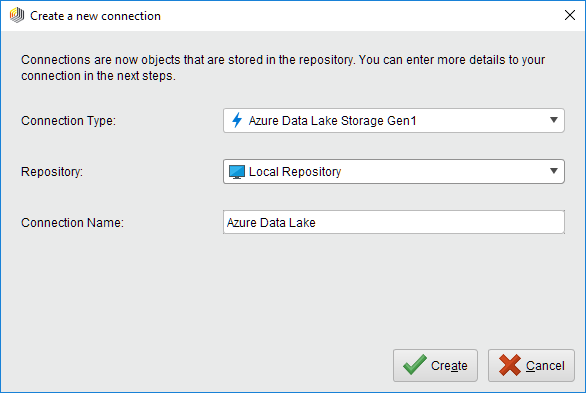
Click on
 Create and switch to the Setup tab in the Edit connection dialog.
Create and switch to the Setup tab in the Edit connection dialog.Fill in the Connection details of your Azure Data Lake Storage Gen1 account. Specify the Tenant ID, Account FQDN (fully qualified domain name), Client ID (web application ID), Client Key (password to access the web application).
While not required, we recommend testing your new Azure Data Lake Storage Gen1 Connection by clicking the
 Test connection button.
If the test fails, please check whether the details are correct.
Test connection button.
If the test fails, please check whether the details are correct.Click
Save to save your Connection and close the Edit connection dialog. You can now start using the Azure Data Lake Storage operators.
Read from Azure Data Lake Storage
The ![]() Read Azure Data Lake Storage operator reads data from your Azure Data Lake Storage Gen1 account.
The operator can be used to load arbitrary file formats, since it only downloads and does not process the files.
To process the files you will need to use additional operators such as Read CSV, Read Excel, or Read XML.
Read Azure Data Lake Storage operator reads data from your Azure Data Lake Storage Gen1 account.
The operator can be used to load arbitrary file formats, since it only downloads and does not process the files.
To process the files you will need to use additional operators such as Read CSV, Read Excel, or Read XML.
Let us start with reading a simple csv file from Azure Data Lake Storage.
Drag a Read Azure Data Lake Storage operator into the Process Panel. Select your Azure Data Lake Storage Gen1 Connection for the connection entry parameter from the Connections folder of the repository you stored it in by clicking on the
 button next to it:
button next to it: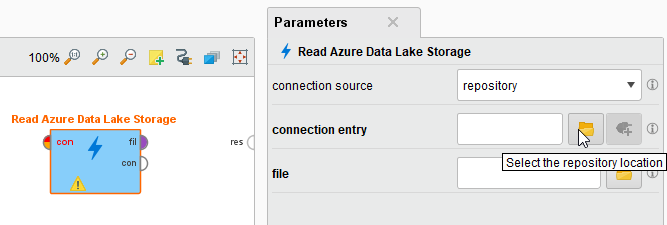
Alternatively, you can drag the Azure Data Lake Storage Gen1 Connection from the repository into the Process Panel and connect the resulting operator with the Read Azure Data Lake Storage operator.
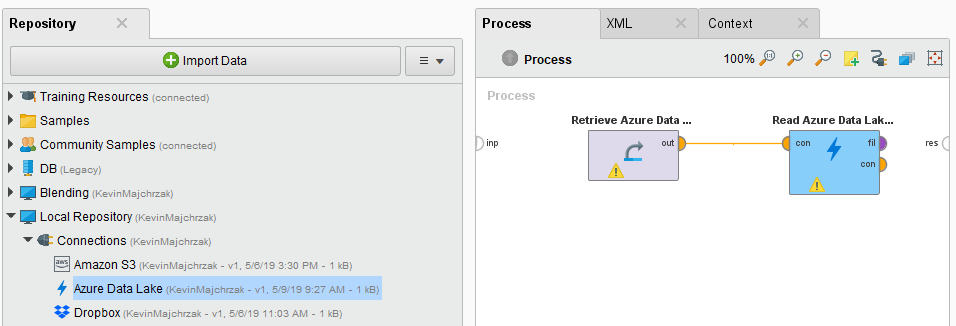
Click on the file chooser button
to view the files in your Azure Data Lake Storage Gen1 account.
Select the file that you want to load and click Open.
Note that you need to have Read and Execute access to the root directory, if you want to use the file browser starting from the root folder. If you do not have that permission, you can type a path into the parameter field.
If you have access to the parent folder of that path (file or directory) and Execute access up to the root folder, you can open the file browser. Or you can always use a manually typed path and use the operator with that (in that case, permission is only checked during runtime).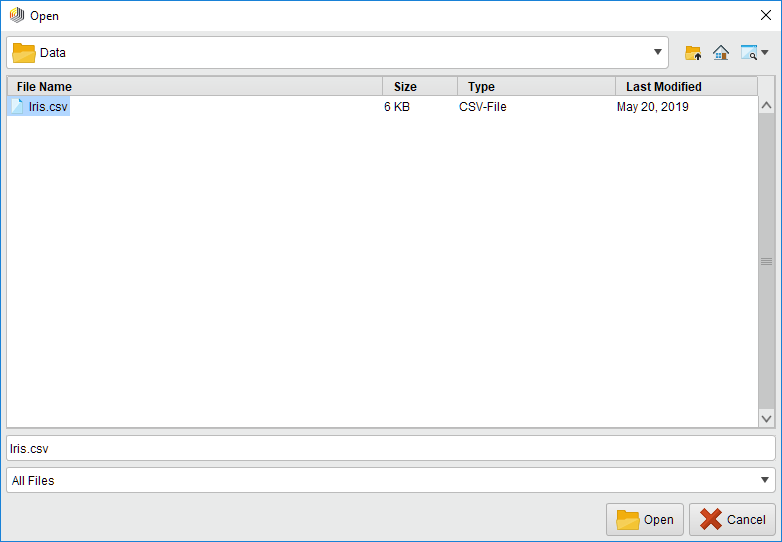
As mentioned above, the
Read Azure Data Lake Storage operator does not process the contents of the specified file.
In our example, we have chosen a csv file (a comma separated values file).
This file type can be processed via the Read CSV operator.Add a Read CSV operator between the
Read Azure Data Lake Storage operator and the result port. You may set the parameters of the Read CSV operator - such as column separator -, depending on the format of your csv file: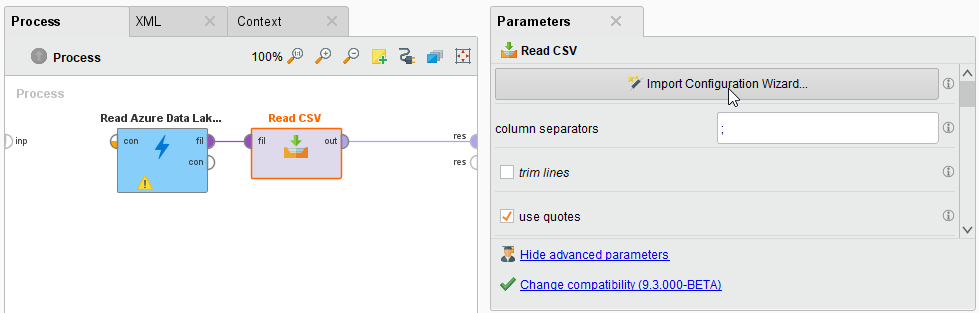
Run
 the process! In the Results perspective, you should see a table containing the rows and columns of your choosen csv file:
the process! In the Results perspective, you should see a table containing the rows and columns of your choosen csv file:
You could now use further operators to work with this document, e.g., to determine the commonness of certain events.
To write results back to Azure Data Lake Storage, you can use the ![]() Write Azure Data Lake Storage operator.
It uses the same Connection Type as the
Write Azure Data Lake Storage operator.
It uses the same Connection Type as the ![]() Read Azure Data Lake Storage operator and has a similar interface.
You can also read from a set of files in an Azure Data Lake Storage directory, using the
Read Azure Data Lake Storage operator and has a similar interface.
You can also read from a set of files in an Azure Data Lake Storage directory, using the ![]() Loop Azure Data Lake Storage operator.
For this you need to specify the connection entry and the folder that you want to process, as well the steps of the processing loop with nested operators. For more details please read the help of
the
Loop Azure Data Lake Storage operator.
For this you need to specify the connection entry and the folder that you want to process, as well the steps of the processing loop with nested operators. For more details please read the help of
the ![]() Loop Azure Data Lake Storage operator.
Loop Azure Data Lake Storage operator.