You are viewing the RapidMiner Radoop documentation for version 9.7 - Check here for latest version
Hortonworks Data Platform (HDP) 2.5.x, 2.6.x and 3.x
The following describes setup for HDP 2.5.0, 2.6.0, 3.0 and 3.1. Setup for other HDP versions should be similar.
Configuring the cluster
If there are restrictions on Hive commands on your cluster (for example, SQL Standard Based Hive Authorization is enabled on it), then the change of certain properties through HiveServer2 must be explicitly enabled. This is required if you get the following error message when running a Full Test in RapidMiner Radoop: Cannot modify radoop.operation.id at runtime. In this case a property must be added on the Ambari interface to resolve this issue.
- Login to the Ambari interface.
- Navigate to the Hive / Configs / Advanced configuration page
Add the
hive.security.authorization.sqlstd.confwhitelist.appendsetting as a new property to both Custom hive-site and Custom hiveserver2-site. The value should be the following (it must contain no whitespaces):radoop\.operation\.id|mapred\.job\.name|hive\.warehouse\.subdir\.inherit\.perms|hive\.exec\.max\.dynamic\.partitions|hive\.exec\.max\.dynamic\.partitions\.pernode|spark\.app\.name|hive\.remove\.orderby\.in\.subquery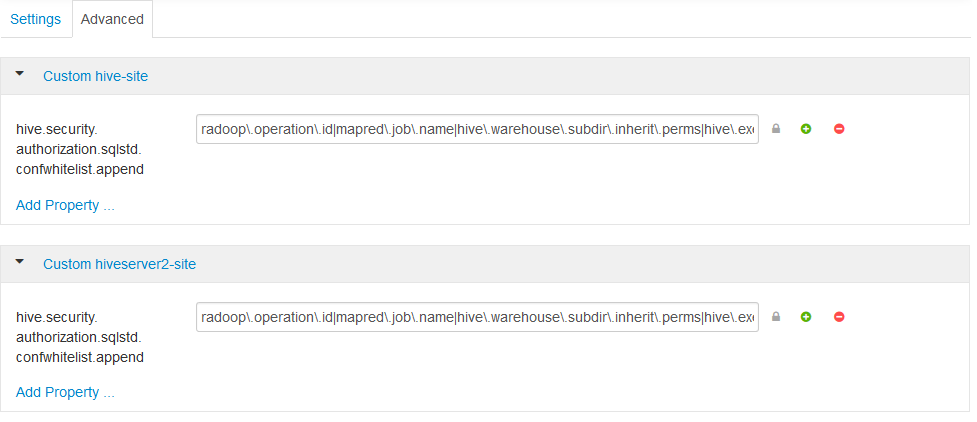
Save the configuration and restart the proposed services.
For a more detailed explanation, see the Hadoop security section.
To enable Spark operators in RapidMiner Radoop, make the following changes in the Connection Settings dialog:
Select the appropriate Spark Version option in the Spark Settings. If Spark is installed with Ambari, the Spark Version depends on the cluster's HDP version.
HDP version | Spark assembly JAR location 3.1.x| Spark 2.3 (HDP) 3.0.x| Spark 2.3 (HDP) 2.6.x| Spark 1.6 or Spark 2.1 / Spark 2.2 2.5.x| Spark 1.6 or Spark 2.0
Set the Assembly Jar Location / Spark Archive path to point to the Spark location on your cluster. The following table contains the default local locations depending on your HDP version. Refer to your Hadoop administrator if the specified path does not seem to work.
HDP version | Spark 1.x assembly JAR location | Spark 2.x archive path 3.1.x||
local:///usr/hdp/current/spark2-client/jars/3.0.x||local:///usr/hdp/current/spark2-client/jars/2.6.x|local:///usr/hdp/current/spark-client/lib/spark-hdp-assembly.jar|local:///usr/hdp/current/spark2-client/jars/2.5.x|local:///usr/hdp/current/spark-client/lib/spark-hdp-assembly.jar|
Notes on security
When connecting to a Kerberized HDP 3.0+ cluster, you have to provide a keytab file in your Radoop connection. (Using password authentication is not supported starting with HDP 3.0).
If you receive a permission error during connection Full Test, verify that:
- The
/user/<hadoop_username>directory exists on the HDFS and is owned by <hadoop_username>. (If the Hadoop username setting is empty, the client OS username is used.) - The <hadoop_username> has write privileges on
/user/historydirectory on the HDFS.
SQL Standard Based Hive Authorization may require that the user running HiveServer2 owns the files and directories loaded into Hive. This can disrupt the normal operation of RapidMiner Radoop. In case of a permission error, consult your Hadoop administrator.