You are viewing the RapidMiner Scoring-agent documentation for version 9.8 - Check here for latest version
Score data
After installing a deployment on the Scoring Agent, you can use the exposed web services to score data.
Web service URLs
As explained in the section on how to create a deployment, each top-level process of a deployment is available as a web service on the Scoring Agent. The generic URL is defined as
http://$SA_HOST/services/$folderName/$processName
Where
$SA_HOSTis the host name of the Scoring Agent (e.g.localhost:8090)$folderNameis the root folder of the deployment on RapidMiner Server (e.g.score-fraud)$processNameis the name of a top-level process (e.g.score-v1)
In case of our example the URL of our scoring web service looks like this:
http://localhost:8090/services/score-fraud/score-v1
Web service input
Each web service endpoint accepts POST requests with either application/json or text/plain content type.
We recommend to use the JSON input if possible because the performance is better than the one with text/plain input.
JSON input
JSON input will automatically be transformed to an ExampleSet which will be provided to the first input port of the process. You can submit one row of data or multiple rows. For a single row of data, the JSON input format looks like this:
{
"data":[
{
"age":"21",
"gender":"male",
"payment_method":"credit card"
}
]
}
Here's an example process that will read the input, apply a model, and return the result on the output port:
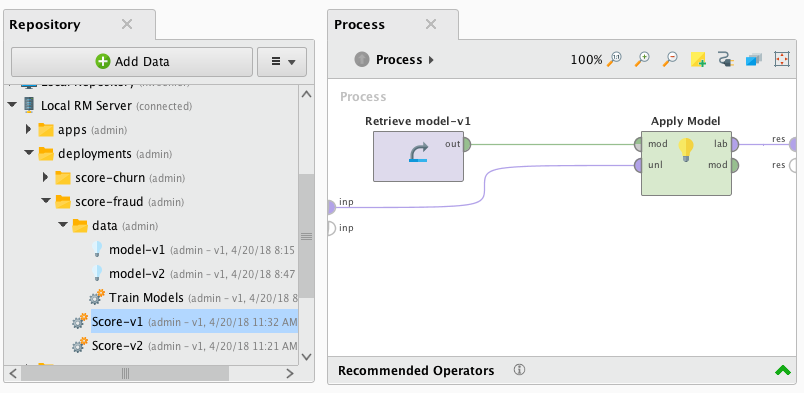
You can make the HTTP POST score request using any HTTP command line tool.
For example, here curl is used to make a score request, with JSON input:
curl -H "Content-Type: application/json" -X POST -d '{ "data":[ { "age":"21", "gender":"male", "payment_method":"credit card" } ]}' http://$SA_HOST/services/$folderName/$processName
Alternatively, you can use a Python package provided by RapidMiner to call the deployed scoring service from Python:
import pandas as pd
import rapidminer
df = pd.DataFrame({"age":[21], "gender":["male"], "payment_method":["credit card"]})
sc = rapidminer.Scoring("http://$SA_HOST", "$folderName/$processName")
prediction = sc.predict(df)
Read more: RapidMiner and Python
Text input
Text input will be provided as a FileObject to the first input port of the process.
"age","gender","payment_method" 21,"male","credit card" 43,"female","cheque"
Here's an example process that will read the data via the Read CSV operator, apply a model, and return the result on the output port:
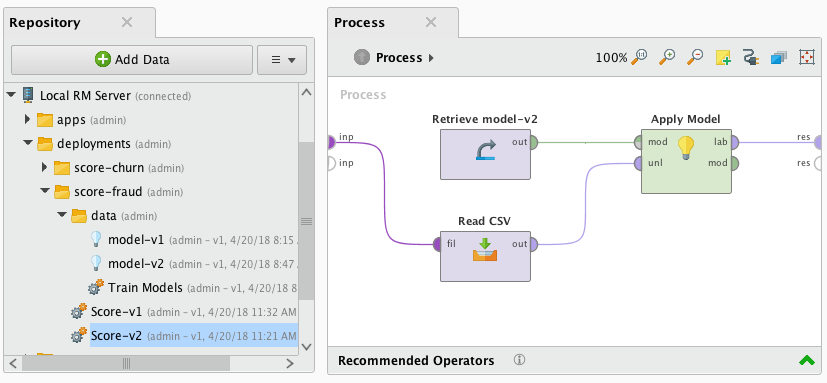
Web service output
The output of the Scoring Agent web service will always be a JSON representation of the ExampleSet that was provided to the first output port of the scoring process.
Here's an example of a possible JSON output from the web service:
{
"data":[
{
"age":"21",
"gender":"male",
"payment_method":"credit card",
"prediction(fraud)": "Fraud",
"confidence(fraud)": 0.721,
},
{
"age":"42",
"gender":"female",
"payment_method":"cheque",
"prediction(fraud)": "No Fraud",
"confidence(fraud)": 0.9921,
}
]
}
Parameterized requests
Web service requests can be parameterize via query parameters in case the scoring process declares macros via the context of the RapidMiner process.
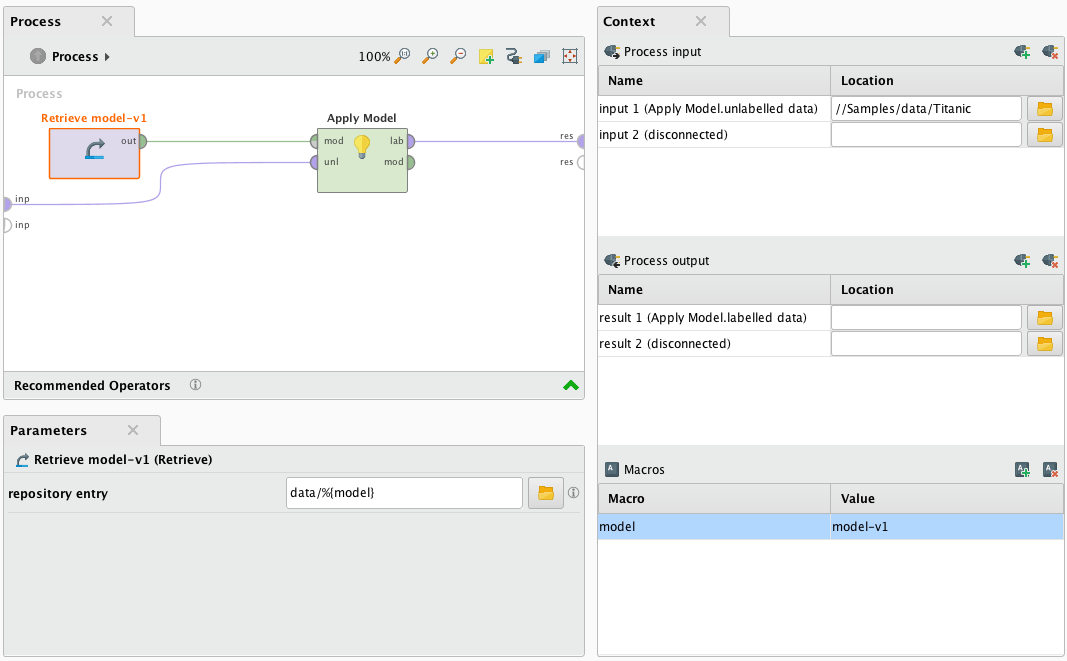
In the given example, a macro model is declared and used in the Retrieve Model operator to dynamically load a model.
Each context macro can be set via query parameters of the same name during a scoring request. For example setting the
model macro is possible via the following request URL:
http://$SA_HOST/services/$folderName/$processName?model=DecisionTree