Configuring Radoop Connections in Altair AI Studio
Radoop connections can be saved as connection objects to repositories and projects, enabling easy sharing and collaboration for Radoop processes, as well as Altair AI Hub executions.
Creating, configuring and using Radoop connections becomes a two-step task:
- Creating, configuring and testing the Radoop connection
- Exporting the Radoop connection to a repository or project
Creating, configuring and testing the Radoop connection
You can configure connections between Radoop in Altair AI Studio and one or more Hadoop clusters from the Manage Radoop Connections and Connection Settings dialogs. You can access these dialogs from the Connections menu, the Hadoop Data view, or the Design view. After configuring and saving the connection entries, you can test them before deployment. The test validates the connection to the cluster and verifies that the connection settings comply with the Radoop requirements described in the section on prerequisites.
There are three methods to create a Radoop connection. We strongly recommend the first.
If you have access to cluster manager software (Cloudera Manager), we strongly recommend using the
 Import from Cluster Manager option. This method is the simplest one.
Import from Cluster Manager option. This method is the simplest one.If you do not use or do not have access to a cluster manager, but can ask for the client configuration files, then use the
 Import Hadoop Configuration Files option.
Import Hadoop Configuration Files option.Otherwise, you always have the option to
 Add Connection Manually. This last option also allows you to import a Radoop connection that someone shared with you by clicking on the Edit XML... button, once the Connection Settings dialog appears.
Add Connection Manually. This last option also allows you to import a Radoop connection that someone shared with you by clicking on the Edit XML... button, once the Connection Settings dialog appears.
Note: When configuring Radoop, you must provide the internal domain name or IP address of the master node (that is, the domain name or IP address that the master node knows about itself). See the networking setup overview for details on how to ensure that your data is safe from unauthorized access.
Basic Radoop connection configuration
Once Radoop is installed, you can create a connection.
Restart Altair AI Studio so that it recognizes the Radoop extension. Once it restarts, you will see a new
 Manage Radoop Connections option in the Connections menu:
Manage Radoop Connections option in the Connections menu:
Select the
Manage Radoop Connections menu item and the Manage Radoop Connections window opens: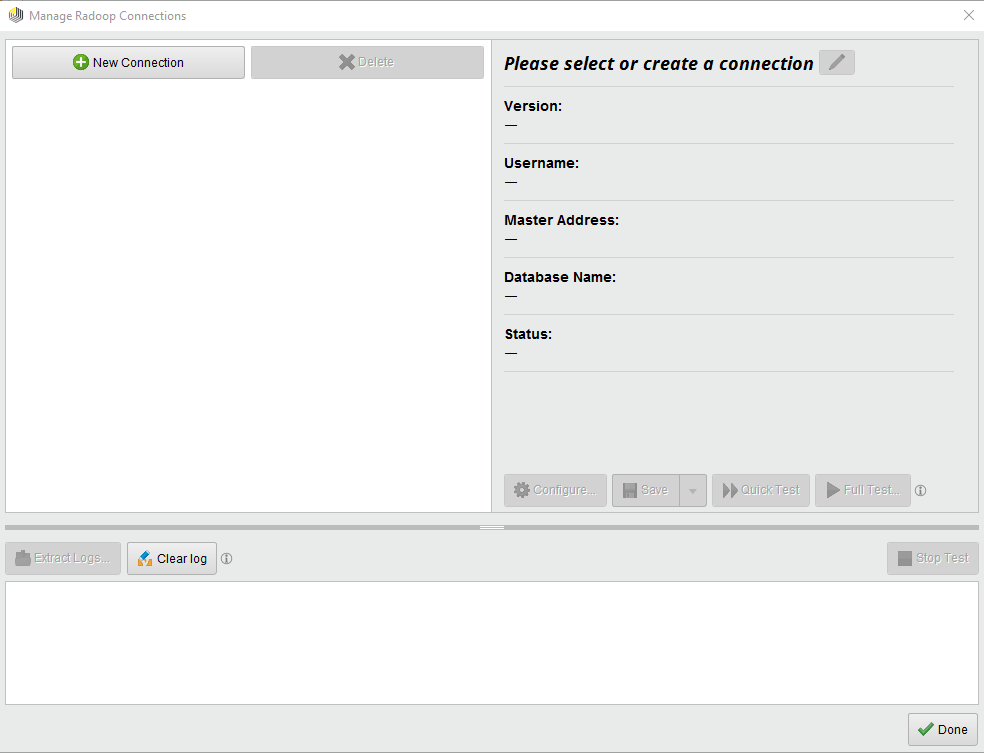
For more details on this dialog, see Manage Radoop Connections section below.
Click on
 New Connection button and choose Add Connection Manually:
New Connection button and choose Add Connection Manually: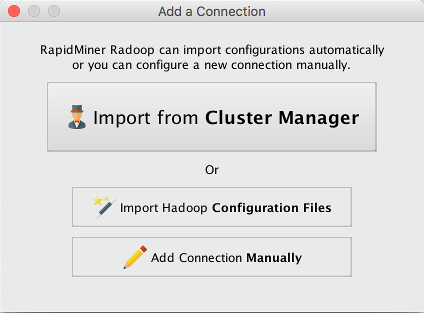
If you wish to create the connection by importing client configuration files or by using a cluster management service, read the Importing Hadoop configuration section.
You can edit the connection properties in the Connection Settings dialog.
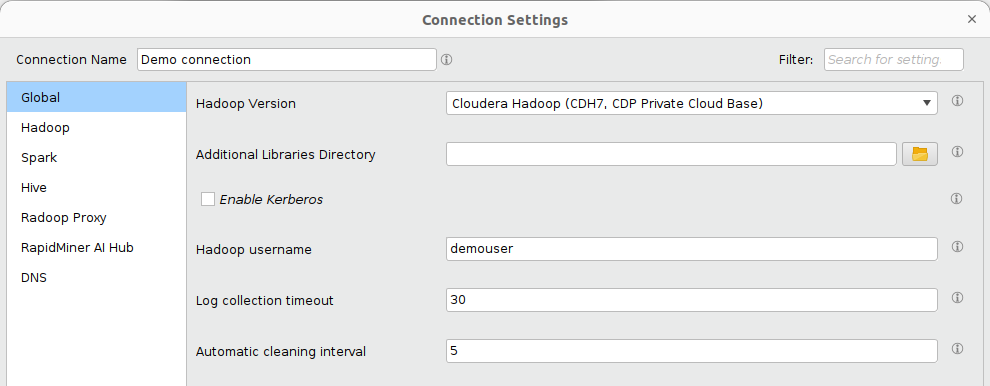
You can provide the name of the connection at the top of the dialog. Additional settings can be configured by selecting the appropriate tab on the left side. Complete the required connection fields listed below. Note that DNS and reverse DNS should work for all specified addresses, so the client machine must have access to the network name resolution system of the cluster or be able to resolve the addresses locally. To make the network configuration easier, the DNS tab provides a configuration option for specifying IP address - hostname(s) entries in a hosts file format. This setting has priority over any other mechanisms for DNS and reverse DNS resolution.
Tab Field Description Global Hadoop Version The distribution that defines the Hadoop version type for this connection. Hadoop NameNode Address Address (usually hostname) of the node running the NameNode service. Hadoop Resource Manager Address Address (usually hostname) of the node running the Resource Manager service. Hive Hive Server Address Address (usually hostname) of the node running the Hive Server or the Impala Server. Spark Spark Version Spark version available on the cluster. Spark Assembly Jar Location / Spark Archive (or libs) path The HDFS location or local path (on all cluster nodes) of the Spark Assembly Jar file / Spark Jar files. For further details, see Advanced connection settings section below.
Click
 OK to create the connection entry.
OK to create the connection entry.Click
 Save to add the entry to the available connections.
Save to add the entry to the available connections.Test the connection between Radoop and the Hadoop cluster. If necessary, and with the assistance of your Hadoop administrator, set the advanced settings based on the distribution specific notes.
Your connection settings are saved in a file called radoop_connections.xml in your .RapidMiner directory.
Importing a connection
Configuring a connection manually can be cumbersome for a more complicated cluster. In this case using one of the connection import features is recommended. There are two options: you can create a connection using the cluster's client configuration files, or by providing the URL and credentials for the cluster's management service (Cloudera Manager).
Importing Hadoop configuration files
You can create Radoop connections by setting up its parameters from client configuration files. To do so, choose ![]() Import Hadoop Configuration Files option when adding a new connection. Set the location of the file in the following dialog:
Import Hadoop Configuration Files option when adding a new connection. Set the location of the file in the following dialog:
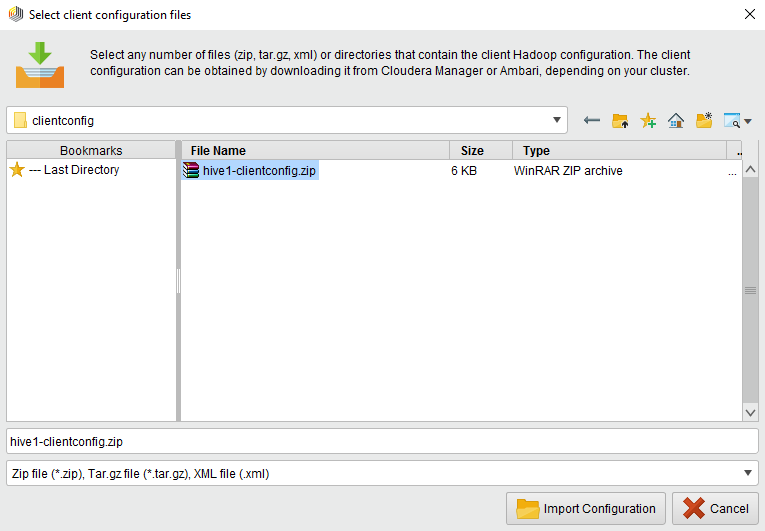
You can select one or more folder(s) or compressed file(s) (such as zip or tar.gz) containing the configuration XML documents, or you can simply import single xml files. You can easily get hold of these files by using the distributor's Hadoop management tool.
Click ![]() Import Configuration and wait until a popup window shows the result of the import process:
Import Configuration and wait until a popup window shows the result of the import process:
 Success: You can go on with the next step.
Success: You can go on with the next step. Warning: Some fields will be missing, these can be provided in the next step.
Warning: Some fields will be missing, these can be provided in the next step.  Show details button informs you about the problem(s).
Show details button informs you about the problem(s). Failure: You need to go
Failure: You need to go  Back and choose the appropriate file(s).
Back and choose the appropriate file(s).
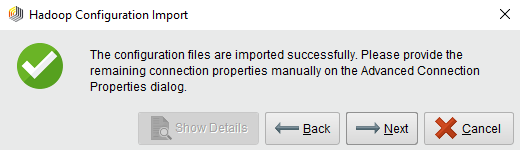
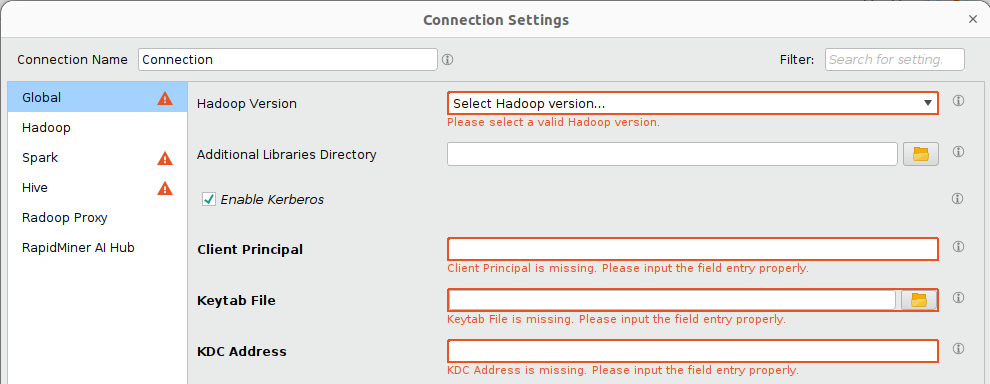
Clicking ![]() Next will lead you to the Connection Settings dialog, where you will find all the properties that could be imported automatically. Some required fields might still be missing. The editor highlights them with a red border and an error message. If a tab contains fields with missing values, it is marked with an error sign.
Next will lead you to the Connection Settings dialog, where you will find all the properties that could be imported automatically. Some required fields might still be missing. The editor highlights them with a red border and an error message. If a tab contains fields with missing values, it is marked with an error sign.
Importing from a Cluster Manager
You can create a connection by providing the URL and the credentials for the cluster's management service. In this case, select the ![]() Import from Cluster Manager option when adding a new connection, to obtain the following dialog:
Import from Cluster Manager option when adding a new connection, to obtain the following dialog:
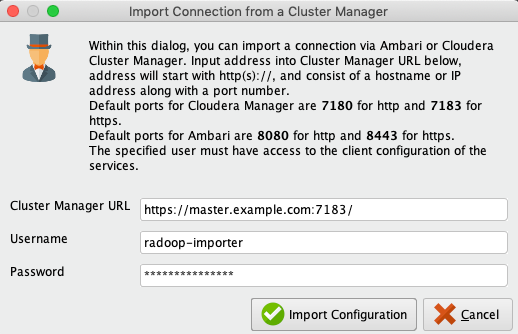
The following fields need to be filled in:
- Cluster Manager URL: The URL of the cluster's management service. For CDH connections, this is Cloudera Manager, running by default on port 7180 (http) or 7183 (https). Please take care of the protocol prefix (usually http, https). If the protocol is missing, "http://" will be used automatically.
- Username: The username for the cluster manager. Please note that the user needs to have privileges for the client configuration. Read-only permissions are sufficient for retrieving most connection properties. Using an admin user is not required.
- Password: The password for the provided cluster manager user.
After filling in the fields, click ![]() Import Configuration to start the import process.
If the cluster manager manages more than one cluster, the following input dialog will pop up. Select the name of the cluster you want to connect to.
Import Configuration to start the import process.
If the cluster manager manages more than one cluster, the following input dialog will pop up. Select the name of the cluster you want to connect to.
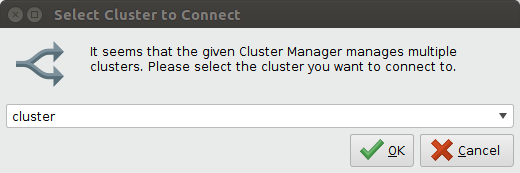
The connection import can have two outcomes:
- Success: You can go on with the next step.
- Failure: You need to go Back and fix the URL or the credentials. The detailed error can be seen if you click the Show Details button.
- If the Failure is due to an untrusted certificate, user will be notified and shown the certificate details and be provided the option to trust the certificate and continue with importing from the Cluster Manager.
When the connection is successfully imported, the Connection Settings dialog will pop up. Here you can change the name of the connection, and complete the connection configuration manually.
A required field with missing values is highlighted with a red border and an error message. A tab containing fields with missing values is marked with an error sign.
A field whose default value may need to be changed is highlighted with an orange border, and the tab is marked with a warning sign.
During Radoop connection creation from an import duplicate properties maybe detected.
If a duplicate property is detected, deconfliction with the previous property value works as follows.
Deconfliction is based on property origin and is resolved in the following descending order:
- yarn-site origin
- core-site origin
- other origins in the order of processed
Priority within same origin, follows sequential read ordering.
If a property value is replaced, an INFO level log is provided stating what key, value/origin was and what value/origin is now being applied.
Manage Radoop Connections window
The Manage Radoop Connections window shows your already configured connections and allows you to edit them, or create and test new connections:
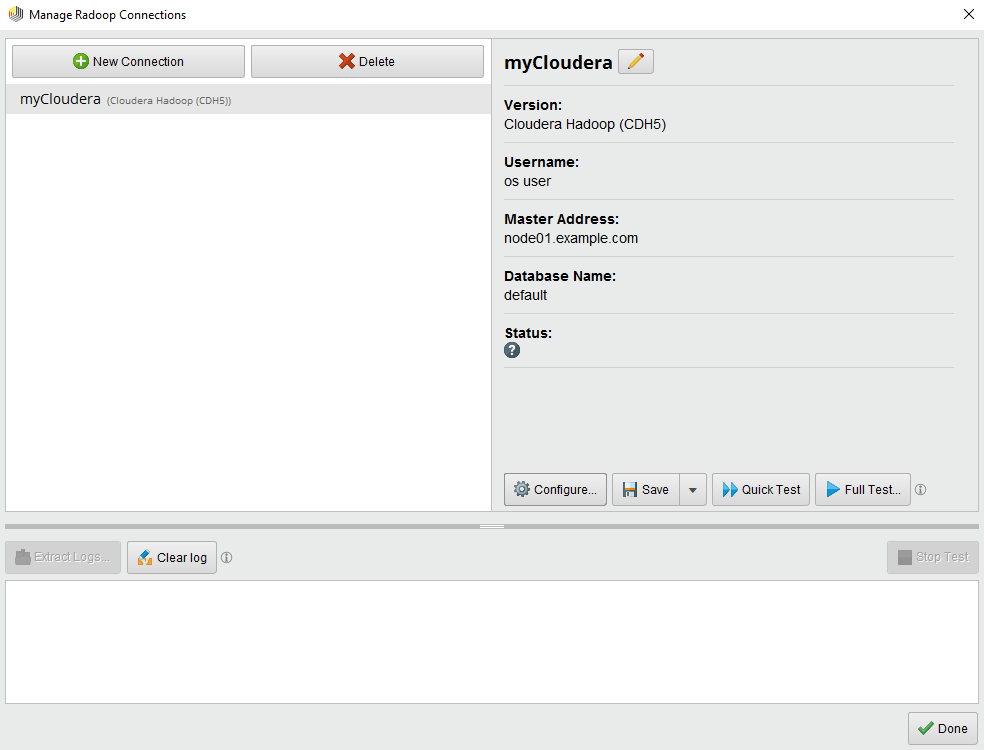
This window consists of 3 panels. The upper left panel lists all known connection entries. For each entry, one or more icons may be present showing some additional information, namely:
 Spark is configured for this connection
Spark is configured for this connection The connection uses Impala as query engine
The connection uses Impala as query engine Connection to a secure cluster
Connection to a secure cluster
The basic properties of the currently selected connection are gathered on the right-hand side panel. There are also buttons executing several actions available on the selected connection:
 Configure...: Opens the Connection Settings dialog where you can configure the connection properties. Check the Advanced connection settings section for more details.
Configure...: Opens the Connection Settings dialog where you can configure the connection properties. Check the Advanced connection settings section for more details.- Save: Saves the currently displayed connection.
 Save As...: Saves a copy of the currently displayed connection. Useful for saving a slightly modified connection while keeping the original entry.
Save As...: Saves a copy of the currently displayed connection. Useful for saving a slightly modified connection while keeping the original entry. Export...: Exports the selected connection to a repository or project. See the next chapter for details.
Export...: Exports the selected connection to a repository or project. See the next chapter for details. Quick Test: Runs a Quick Test on the currently displayed connection.
Quick Test: Runs a Quick Test on the currently displayed connection. Full Test...: Runs a Full Integration Test on this connection. More information on the connection tests can be found in the Testing Radoop connections section.
Full Test...: Runs a Full Integration Test on this connection. More information on the connection tests can be found in the Testing Radoop connections section.- Rename Action: Renames the current connection. Please note that all connection names should be unique.
The lower panel shows logs of the running tests. Several actions can be performed on this panel too:
 Extract logs...: This action creates a bundled zip file containing all relevant logs of your recent Radoop-related activities. See related section for more details.
Extract logs...: This action creates a bundled zip file containing all relevant logs of your recent Radoop-related activities. See related section for more details. Clear logs: Clears the connection log field.
Clear logs: Clears the connection log field. Stop Test: The Stop Test action will halt the currently running test execution (see the Testing Radoop connections section).
Stop Test: The Stop Test action will halt the currently running test execution (see the Testing Radoop connections section).
Testing Radoop cluster connections
Radoop's built-in test functions help with troubleshooting before trouble begins. These tests can be executed from the Manage Radoop Connections window, or as part of an Altair RapidMiner process using the Radoop Connection Test operator.
Basic connection test
Click the ![]() Quick Test button in the Manage Radoop Connections window to test the connection to the cluster. Through a series of simple tests to different components (APIs) on the cluster, the test verifies that the cluster is running and that the Radoop client can access it. You can stop the test anytime by clicking the
Quick Test button in the Manage Radoop Connections window to test the connection to the cluster. Through a series of simple tests to different components (APIs) on the cluster, the test verifies that the cluster is running and that the Radoop client can access it. You can stop the test anytime by clicking the ![]() Stop Test button.
Stop Test button.
Full connection tests
Once your test succeeds, run a complete test (which may take several minutes) by clicking the ![]() Full Test... button. It's possible to customize a full connection test by clicking the
Full Test... button. It's possible to customize a full connection test by clicking the ![]() Customize... button. In this panel you can enable or disable tests, change the timeout and enable or disable the cleaning after the tests. These values are reset to the defaults after closing the Manage Radoop Connections window. Click
Customize... button. In this panel you can enable or disable tests, change the timeout and enable or disable the cleaning after the tests. These values are reset to the defaults after closing the Manage Radoop Connections window. Click ![]() Run to start the test.
Run to start the test.
The full test initiates several jobs and applications on the cluster and then checks the results. By successfully and extensively exercising Radoop interactions with your cluster, you can feel confident in your Radoop process design and execution.
In addition to testing connections when you first create a Radoop configuration, you can use the Full Test if you have an error in process execution or a change in the cluster. The output of the full test results can help identify the root cause of the problem for easier troubleshooting. You can stop the Full Test anytime by clicking the ![]() Stop Test button. Stopping the current test process may take some time.
Stop Test button. Stopping the current test process may take some time.
Note: The cluster connection initial test also starts automatically in the background when you open a process containing a Radoop Nest operator (indicated by the status bar in the bottom right corner of the Altair AI Studio screen).
Radoop Connection Test operator
Running connection tests using the Radoop Connection Test operator is especially useful when validating connections in Altair AI Hub. The operator can be placed inside a Radoop Nest operator and will run connection tests against the Radoop connection specified in the Radoop Nest (both legacy and repository or projects based connections are supported).
Users can select which test set to run. Similarly to the Full Test functionality in the Manage Radoop Connections window explained above, further customization of tests is possible by setting the Test Suite parameter of the operator to Customized Integration Test and then selecting the preferred tests.
Test results are provided as an ExampleSet on the operator's out port, while troubleshooting logs are packaged into a zip file on the operator's log port. This compressed log bundle can be conveniently written to a project or repository for easy retrieval even in secure enterprise environments.
Check out the operator's tutorial process for a useful example.
Advanced connection settings
You can use the Connection Settings dialog to edit the connection parameters. For example, you can change port numbers or define arbitrary parameters for Hadoop and Hive using key-value pairs. Do not modify the connection settings without first consulting with your organization's IT administrator. To open the Connection Settings dialog, click the ![]() Configure... button from the Manage Radoop Connections window.
Configure... button from the Manage Radoop Connections window.
Note: The fields displayed depend on the selections (for example, the selected Hadoop version). Also, some fields prepopulate based on the Hadoop version selection from the basic settings. If a field is bold in the window, it is required.
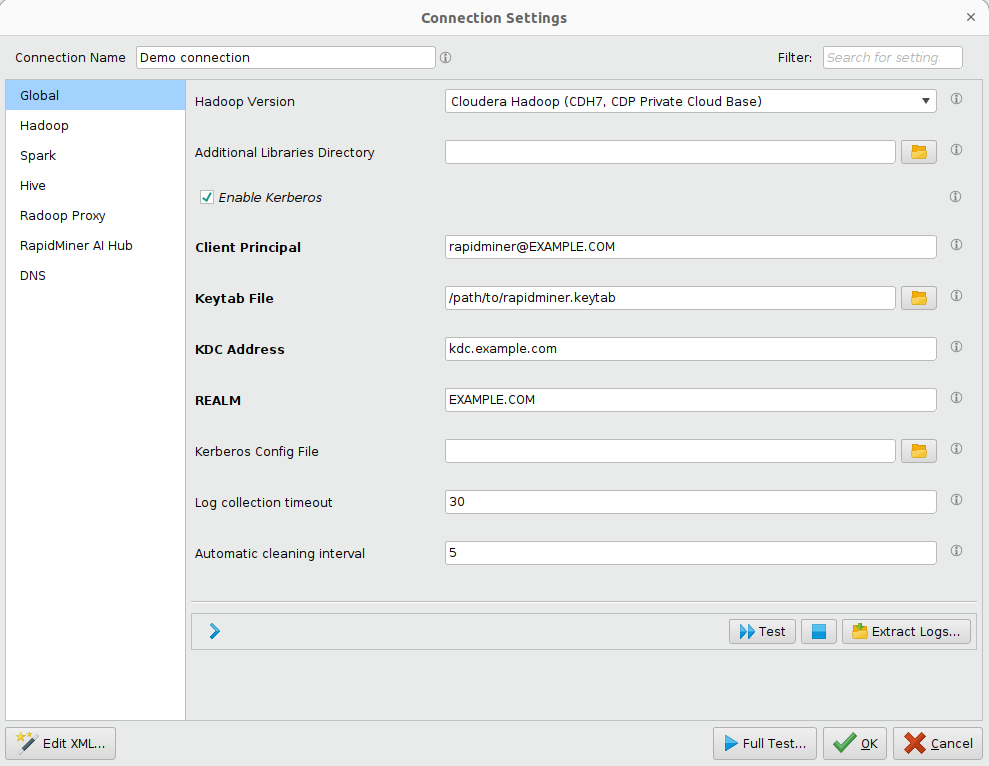
The Connection Settings dialog has multiple tabs. The following tables describe the fields in each tab. For advanced configuration details related to your environment, see the distribution specific notes.
Global
| Field | Description |
|---|---|
| Hadoop Version | The distribution that defines the Hadoop version type for this connection. |
| Additional Libraries Directory | Any additional libraries (JAR files) on the client needed to connect to the cluster (optional, for expert users only). |
| Enable Kerberos | Check this box to connect to a Hadoop cluster secured by Kerberos. |
| Client Principal | Only with Kerberos security enabled and Server impersonation disabled. Principal of the user accessing Hadoop. The format is primary[/<instance>]@<REALM>, where primary is usually the user name, instance is optional, and REALM is the Kerberos realm. Example: user/client.rapidminer.com@RAPIDMINER.COM. |
| KeyTab File | Path of the user keytab file on the client machine. Enter or browse to the file location. |
| KDC Address | Only with Kerberos security enabled. Address of the Kerberos Key Distribution Center. Example: kdc.rapidminer.com. |
| REALM | Only with Kerberos security enabled. The Kerberos realm. It is usually the domain name in upper-case letters. Example: RAPIDMINER.COM. |
| Kerberos Config File | Only with Kerberos security enabled. To avoid configuration differences between the machine running Altair RapidMiner and the Hadoop cluster, it is good practice to provide the Kerberos configuration file (usually krb5.conf or krb5.ini). Obtain this file from your security administrator. Enter or browse to the file location. |
| Log collection timeout | Timeout, in seconds, for the collection of the YARN aggregated logs. 0 means that the feature is turned off. Turning off this feature is recommended if the YARN log aggregation is disabled for your cluster. |
| Automatic cleaning interval | Interval, in days, for the Radoop automatic cleaning service. Radoop will clean every temporary table, file and directory that is older than the given threshold. Zero value means no automatic cleaning is performed. |
| Hadoop Username | The name of the Hadoop user. In most cases, the user must have appropriate permissions on the cluster. For a new connection, the default is the OS user. |
Hadoop
| Field | Description |
|---|---|
| NameNode Address | Address (usually hostname) of the node running the NameNode service. (Requires a working network name resolution system.) |
| NameNode Port | Port of the NameNode service. |
| Resource Manager Address | Address (usually hostname) of the node running Resource Manager service. |
| Resource Manager Port | Port of the Resource Manager service. |
| JobHistory Server Address | Address (usually hostname) of the node running the Job History Server service. |
| JobHistory Server Port | Port of the Job History Server service. |
| Connection timeout | Timeout, in seconds, for Radoop to wait for a connection to become available. 0 means default value (30). Increasing the value will help mitigate timeouts caused by high network or cluster latency. |
| Retrieve Service Principals from Hive | Only with Kerberos security enabled. If checked, Radoop automatically retrieves all other service principals from Hive for easier configuration. Disable this setting only if there is a problem accessing other services. |
| NameNode Principal | Only with Kerberos security enabled and Hive principal retrieval disabled. Principal of the NameNode service. You can use the _HOST keyword as the instance. Example: nn/_HOST@RAPIDMINER.COM |
| Resource Manager Principal | Only with Kerberos security enabled and Hive principal retrieval disabled. Principal of the ResourceManager service. You can use the _HOST keyword as the instance. Example: rm/_HOST@RAPIDMINER.COM |
| JobHistory Server Principal | Only with Kerberos security enabled and Hive principal retrieval disabled. Principal of the JobHistoryServer service. You can use the _HOST keyword as the instance. Example: jhs/_HOST@RAPIDMINER.COM |
| HDFS directory for temporary files | HDFS directory for temporary files. Defines the path in which Radoop stores temporary files on the cluster. The client user that runs Radoop must have permission to create this directory if it does not exist, and/or must have read and write permission on the directory. |
| Advanced Hadoop Parameters | Key-value properties to customize the Hadoop connection and Radoop's Yarn/MapReduce jobs. Some connections require certain advanced parameters. For detailed information, see the distribution specific notes. |
Spark
| Field | Description |
|---|---|
| Spark Version | Spark Version available on the cluster. For more information on using Spark operators, see the Configuring Spark section. |
| Use default Spark path | Use the default Spark Assembly / Archive path for the selected Hadoop version. Note that your cluster may have different settings, in which case you must disable this setting and configure the path properly. Also note that multiples Spark versions may be installed on the cluster, and this heuristic may only pick one of them. |
| Assembly Jar Location / Spark Archive (or libs) path | The HDFS location or local path (on all cluster nodes) of the Spark Assembly Jar file / Spark Jar files. |
| Spark Resource Allocation Policy | The resource allocation policy for Spark jobs. The default - Dynamic Resource Allocation starting from 8.1.1 and Static, Heuristic Configuration in 8.1.0 - is typically applicable. See more Spark policy information. |
| Resource Allocation % | Percentage of cluster resources allocated for a Spark job. This field is only enabled when Static, Heuristic Configuration is the Spark resource allocation policy. |
| Use custom PySpark archive | Check this box if you want to provide your own PySpark archives. |
| Custom PySpark archive paths | Only when Use custom PySpark archive option is enabled. Set of archives used as PySpark libraries for PySpark job submissions. See the instructions for configuring custom PySpark/SparkR archives. |
| Use custom SparkR archive | Check this box if you want to provide your own SparkR archive. |
| Custom SparkR archive path | Only when Use custom SparkR archive option is enabled. Archive used as the SparkR library for SparkR job submissions. Set of archives used as PySpark libraries for PySpark job submissions. See the instructions for configuring custom PySpark/SparkR archives. |
| Spark Memory Monitor GC threshold | If this percentage of the time in lookback seconds is spent with GC, the Memory Monitor will kill the process. |
| Spark Memory Monitor Lookback Seconds | Window size in number of seconds the Spark GC usage monitor will analyze. |
| Advanced Spark Parameters | Key-value properties that customize Radoop's Spark jobs. See the instructions for configuring Spark. |
Hive
| Field | Description |
|---|---|
| Hive Version | Select the appropriate Data Warehouse System — HiveServer2 (Hive 0.13 or newer) or Impala. Alternatively, you can select Custom HiveServer2 and provide your own Hive jars. |
| Custom Hive Lib Directory | Only with Custom Hiveserver2 selected. Select a directory that contains the libraries (JAR files) needed to connect to the cluster. |
| Hive High Availability | Check this box if Hive High Availability is activated for this cluster (provided that HiveServer access is coordinated by ZooKeeper). |
| Hive Server Address/Impala Server Address | Address (usually hostname) of the node running the Hive Server or the Impala Server. |
| Hive Port/Impala Port | Port of the Hive Server or Impala Server. |
| Database name | Name of the database to connect to. |
| File Format for Hive | Storage format default for Hive connections. The storage format is generally defined by the Radoop Nest parameter hive_file_format, but this property sets a default for this parameter in new Radoop Nests. It also defines the default settings for new table import on the Hadoop Data View. 'Default format' means use Hive server default (usually TEXTFILE). |
| File Format for Impala | Only with Impala selected. Storage format default for Impala connections. The storage format is generally defined by the Radoop Nest parameter impala_file_format, but this property sets a default for this parameter in new Radoop Nests. It also defines the default settings for new table import on the Hadoop Data View. 'Default format' means use Hive server default (usually TEXTFILE). |
| JDBC URL Postfix | Optional postfix for the JDBC URL. The default is "auth=noSasl" for Impala connections. |
| Username | Username for connecting to the specified database. The default is "hive" for all HiveServer2 version connections. This user should have access to the HDFS directory that Radoop uses for storing files temporarily. If this directory is located in an encryption zone, the user should also have permissions to access the encryption zone key. |
| Password | Password for connecting to the specified database. Radoop uses the cipher.key file to encrypt the password in radoop_connections.xml. |
| Hive Principal | Only with Kerberos security enabled. Principal of the Hive service. The format is primary[/<instance>]@<REALM>, where primary is usually the user name, instance is optional, and REALM is the Kerberos realm. Do not use the _HOST keyword as the instance. If Hive is not configured for Kerberos but uses another authentication mechanism (e.g., LDAP), leave this field empty. Example: hive/node02.rapidminer.com@RAPIDMINER.COM. |
| SASL QoP Level | Level of SASL Quality of Protection. This setting must be the same as the cluster setting. (To find the cluster setting, find the value of hive.server2.thrift.sasl.qop in hive-site.xml; the default is “auth”.) |
| Table prefix | Default Hive temporary table prefix for new processes. You can specify this prefix as a parameter of a Radoop Nest operator. This property only defaults this parameter to the specified value, so different clients or users may easily differentiate their temporary objects on the cluster. |
| Hive command timeout | Timeout, for simple Hive commands that should return, in seconds. Zero means default value (30). This setting defines the time after which Radoop may cancel an atomic operation on the cluster, since the command should finish in a few seconds at most. You may increase this value, if the connection latency is high or may vary in a large interval. |
| Connection pool size | Size of the Hive JDBC connection pool. Increase it if you want to run many operations in parallel (e.g. on Altair AI Hub). |
| Connection pool timeout | Timeout, in seconds, for waiting for an available connection. |
| Hive on Spark / Tez container reuse | Check this box if you would like to benefit from Hive on Spark / Hive on Tez container reuse. |
| Container pool fixed size | Number of Hive on Spark containers if container reuse is enabled for the connection. Container reuse makes Hive on Spark queries run faster by removing the container start time overhead. Please be aware that containers are continuously reserving cluster resources, even when there are no running queries. You can use the idle time setting below to close unused containers and free up resources after an idle period. It is recommended to monitor your cluster resources to find the right setting. If set to 0, an estimated value will be used based on cluster resources. |
| Container pool timeout | Timeout for waiting for an available container, in seconds. Enter 0 to wait for resources indefinitely. |
| Container idle time | Time after idle Hive on Spark / Hive on Tez containers will be closed, in seconds. Enter 0 to disable closing idle containers. |
| UDFs are installed manually | Check this box if the Radoop UDFs are installed on the cluster manually. More information on the manual UDF installation can be found on the Operation and Maintenance page. |
| Use custom database for UDFs | Check this box if a custom database should be used for storing and accessing Radoop UDFs. This is useful when more users (having different project databases and granted privileges) wish to use Radoop. This common database should be accessible by all of them. The UDFs can still be automatically or manually created. |
| Custom database for UDFs | Only when "Use custom database for UDFs" is checked. Define the database dedicated for storing Radoop UDFs (see above). The database must exist. |
| Advanced Hive Parameters | Key-value properties to customize the behavior of Hive. |
Radoop Proxy
| Field | Description |
|---|---|
| Use Radoop Proxy | Check this box if you want to access the Hadoop Cluster through a Radoop Proxy. |
| Radoop Proxy Connection | Only when Radoop Proxy is enabled. This field consists of two dropdown selectors, which together define the Radoop Proxy used for accessing the cluster. The first one defines the location of the Radoop Proxy. Can be local or one of the configured Altair AI Hub repositories. The second one is the identifier of the Radoop Proxy. |
Altair AI Hub
This tab contains some multi-user configuration settings that affect the execution on Altair AI Hub. For more information and best practice solutions, see the relevant sections of Installing Radoop on AI Hub page.
| Field | Description |
|---|---|
| Enable impersonation on AI Hub | Check this box if you want to use an impersonated (proxy) Hadoop user on Altair AI Hub. |
| Server Principal | Only with Kerberos security and AI Hub impersonation enabled. Principal used by Altair AI Hub to access the cluster. The format is primary[/<instance>]@<REALM>, where primary is usually the user name, instance is optional, and REALM is the Kerberos realm. Example: user/server.rapidminer.com@RAPIDMINER.COM. Please note that this setting only affects the execution on Server. |
| Server Keytab File | Only with Kerberos security and Server impersonation enabled. Path of the server keytab file on the server machine. |
| Impersonated user for local testing | Only when impersonation on Altair AI Hub is enabled. Altair AI Hub user to impersonate for testing Altair AI Hub connections locally from Altair AI Studio. |
| Access Whitelist | Regex for Server users who has access to this connection. Leave it empty or use '*' to enable access to all users. |
DNS
| Field | Description |
|---|---|
| Host mapping | IP address - hostname mapping. It is used for DNS and reverse DNS resolution. Contents are expected in a hosts file format (comments, empty lines and multiple aliases are supported). This setting has priority over any other DNS and reverse DNS resolution mechanisms. |
XML connection editor
The Radoop connection XML can be edited manually by clicking the Edit XML... button on the Connection Settings dialog. Please note that this feature should be used carefully as it's easy to make mistakes in a connection entry through the XML editor. The main purpose of the editor is to make connection sharing and copy-pasting some parts of it (e.g. Advanced Hadoop Parameters) much easier. When you close the window with the OK button, your changes appear in the fields of the Connection Settings dialog.
Note: Adding a separate key attribute to <radoop-connection-entry> tag in the XML editor will have no effect. It can only be added in radoop_connections.xml, manually.
Configuring non-default properties
If your Hadoop cluster uses non-default properties, additional key-value pairs may be required. Cluster management tools like Cloudera Manager allow you to download the client configuration files. You may have to add cluster connection-related properties from these files to the Advanced Hadoop Parameters section of the Hadoop tab. See below for single properties that occur to be (re)set frequently, and more complex examples describing the properties required to connect to a cluster with High Availability (HA) enabled. The following tables list the keys of the potentially required client-side settings. The values should be set to the appropriate property values from the client configuration files. Note that not all keys related to these features may be required, the required set of key-value pairs depend on your cluster settings.
Examples for frequently set properties
| Key | Description |
|---|---|
dfs.client.use.datanode.hostname |
Indicates whether clients should use datanode hostnames when connecting to datanodes. Setting it to true may allow to use the public network interface of the datanodes instead of the private one. By default, the property value retrieved from the cluster is used. If not properly set, DataNode networking test (part of the full connection test) will show a warning. Example: see CDH Quickstart VM |
mapreduce.job.queuename |
Queue to which a job is submitted. The system must be configured with this predefined queue, and access must be granted for submitting jobs to it. When using other than the default queue, it must be defined here explicitly. Example: low_priority |
Connecting to an HDFS with high availability
Configuring the connection to an HA HDFS-enabled cluster only requires that you specify the proper Hadoop settings in the Advanced Hadoop Parameters section of the Hadoop tab.
The HA feature eliminates any single point of failure for a cluster by providing a standby (in addition to active) NameNode. HA implements manual switchover and automatic failover to provide continuous availability. The following table lists the settings required for the Radoop client to connect to the cluster. These properties must be configured in each cluster node configuration file. For further details, see your Hadoop documentation.
| Key | Description |
|---|---|
fs.defaultFS (or fs.default.name) |
The default path for Hadoop FS typically contains the NameService ID of the HA-enabled cluster. Example: hdfs://nameservice1 |
dfs.nameservices |
The logical name for the service. Example: nameservice1 |
dfs.ha.namenodes.<nameservice ID> |
Comma-separated list of unique NameNode identifiers. Example: namenode152,namenode92 |
dfs.namenode.rpc-address.<nameservice ID>.<namenode ID> |
RPC address for each NameNode to listen on. Example: node01.example.com:8020 |
dfs.client.failover.proxy.provider.<nameservice ID> |
Class HDFS clients use to contact the active NameNode. Currently there is only one option shipped with Hadoop. Example: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider |
Connecting to a Resource Manager with high availability
Setting the connection to an HA Resource Manager-enabled cluster only requires that you specify the proper Hadoop settings in the Advanced Hadoop Parameters section of the Hadoop tab.
The Resource Manager (RM) HA feature removes a single point of failure (adds redundancy) using an Active/Standby RM pair. The following table lists the settings required for the Radoop client to connect to the cluster. These properties must be configured in each cluster node configuration file. For further details, see your Hadoop documentation.
| Key | Description |
|---|---|
yarn.resourcemanager.ha.enabled |
Enables Resource Manager High Availability. |
yarn.resourcemanager.ha.automatic-failover.enabled |
Enables automatic failover. By default, only enabled when HA is enabled. |
yarn.resourcemanager.ha.automatic-failover.embedded |
When automatic failover is enabled, uses embedded leader-elector to pick the active RM. By default, only enabled when HA is enabled. |
yarn.resourcemanager.zk-address |
Address of the ZK-quorum. Used both for the state-store and embedded leader-election. |
yarn.resourcemanager.cluster-id |
Identifies the cluster. Used by the elector to ensure an RM does not take over as active for another cluster. Example: yarnRM |
yarn.resourcemanager.ha.id |
Identifies the RM in the ensemble. Optional, but if set, ensure that all the RMs have a unique ID. |
yarn.resourcemanager.ha.rm-ids |
Comma-separated list of logical IDs for the RMs. Example: rm274,rm297 |
yarn.resourcemanager.address.<rm-id> |
Service address for each RM ID. |
yarn.resourcemanager.scheduler.address.<rm-id> |
Scheduler address for each RM ID. |
yarn.resourcemanager.resource-tracker.address.<rm-id> |
Resource tracker address for each RM ID. |
yarn.resourcemanager.admin.address.<rm-id> |
RM admin address for each RM ID. |
yarn.resourcemanager.store.class |
The class to use as the persistent store for RM recovery. |
Configuring Spark for a Radoop connection
By configuring Spark for a Radoop connection, you enable the Spark operators. See the exact Spark version requirements for each operator on the Installing Radoop on Altair AI Studio page.
To enable Spark, select a valid Spark version from the dropdown list in the Connection Settings dialog.
You must provide the following mandatory inputs on the Spark tab of the Connection Settings dialog:
| Field | Description |
|---|---|
| Spark Version | Dropdown list to select the version of Spark your cluster supports. If Spark is not on the cluster or unneeded, select None. |
| Assembly Jar location / Spark Archive (or libs) path | The HDFS or local path of the distribution-specific Spark assembly JAR file / Spark JAR files. If you provide a local path then it must be the same on every node in your cluster. Specifying the local path is recommended if Spark is automatically installed (e.g. with Cloudera Manager) on the cluster. For some Hadoop versions, the pre-built Spark assembly JAR can be downloaded from the Apache Spark download page. Some vendors (like Cloudera) provide a distribution-specific Spark assembly JAR. For the HDFS path of the JAR, contact your Hadoop administrator. To install Spark manually, refer to the Spark requirements section. |
| Spark resource allocation policy | Spark needs specification of the cluster resources it is allowed use. See the Spark resource allocation policy descriptions |
| Advanced Spark Parameters | Key-value pairs that can be applied to a Spark-on-YARN job. If the change has no effect on your Spark job, most likely it is ignored by YARN itself. To check the properties in the application log, set spark.logConf to true. |
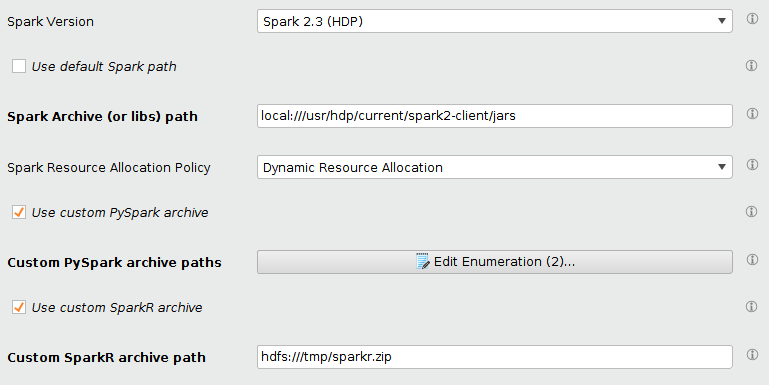
Configuring custom PySpark/SparkR archives for Spark
Radoop is shipped with PySpark and SparkR archives for each minor (x.y) Spark version to support Spark Scripting operator. Using these archives for all sub-versions (x.y.z) is sufficient in most cases. Nevertheless, custom PySpark and SparkR archive options were introduced on the connection editor. When these options are enabled, Radoop uses the user-provided archives to execute Spark Script operator, instead of the ones bundled with Radoop. These archives are usually shipped with the Hadoop distribution together with Spark so typically located close to Spark installation folder. This functionality is handled by the following extra settings:
| Field | Description |
|---|---|
| Use custom PySpark archive | Check this box if you want to provide your own PySpark archives. |
| Custom PySpark archive paths | Only when "Use custom PySpark archive" option is enabled. Set of archives used as PySpark libraries for PySpark job submissions. You will typically need to provide two archives here, pyspark.zip and py4j-*.zip. The exact name and access path of these files depend on the Hadoop and Spark version of your cluster. Since you will need to provide at least two items, this parameter accepts multiple values. Each entry can be provided either as an HDFS location (hdfs:// protocol), as a file which is available on all cluster nodes at the same location (local:// protocol), or as a file on the client machine (file:// protocol). In a sample CDP environment the necessary entries using local paths are local:///opt/cloudera/parcels/SPARK3/lib/spark3/python/lib/pyspark.zip and local:///opt/cloudera/parcels/SPARK3/lib/spark3/python/lib/py4j-0.10.9.5-src.zip. |
| Use custom SparkR archive | Check this box if you want to provide your own SparkR archive. |
| Custom SparkR archive path | Only when "Use custom SparkR archive" option is enabled. Archive used as the SparkR library for SparkR job submissions. This path can be provided either as an HDFS location (hdfs:// protocol) or as a file on the client machine (file:// protocol). WARNING! Specifying archives available on the cluster nodes (local:// protocol) is not supported for this parameter. Therefore if your archive is accessible on a cluster node, you will first need to upload it to HDFS, and use the HDFS location for this parameter. In a sample CDP environment this file is located at /opt/cloudera/parcels/SPARK3/lib/spark3/R/lib/sparkr.zip. In the example shown below, this file was uploaded to hdfs:///tmp/sparkr.zip HDFS location, which is then referenced by this parameter. |
Spark resource allocation policies
Radoop supports the following resource allocation policies:
Dynamic Resource Allocation
Default option starting from 8.1.1. While this policy requires configuration on the server, many server already have this installed.
With this policy you may need to configure an external shuffle service on the cluster. For more information about the required cluster configuration steps see the Spark Dynamic Allocation documentation.
The following properties may be defined under Advanced Spark Parameters on the Spark tab of Connection Settings dialog:
- `spark.dynamicAllocation.minExecutors` - `spark.dynamicAllocation.maxExecutors`Cluster specific info
Static, Heuristic Configuration
- This is the default policy in 8.1.0 and previous versions. If you use this option, you do not need to set any advanced resource allocation settings. The Resource Allocation % field sets the percentage of cluster resources (cluster memory, number of cores) to be used for a Spark job. Note that if you set this value too high, other jobs on the cluster might suffer. The default value is 70%.
Static, Default Configuration
- A policy that uses Spark's default settings for resource allocation. This value is very low and may not support a real cluster, but it may be a viable option for VMs/sandboxes.
Static, Manual Configuration
- This policy requires that you set the following properties under Advanced Spark Parameters on the Spark tab of the Connection Settings dialog. The Spark documentation describes each property. (The corresponding Spark on YARN command line arguments are shown in parentheses.)
spark.executor.cores(--executor-cores)spark.executor.instances(--num-executors)spark.executor.memory(--executor-memory)- (optional)
spark.driver.memory(--driver-memory)
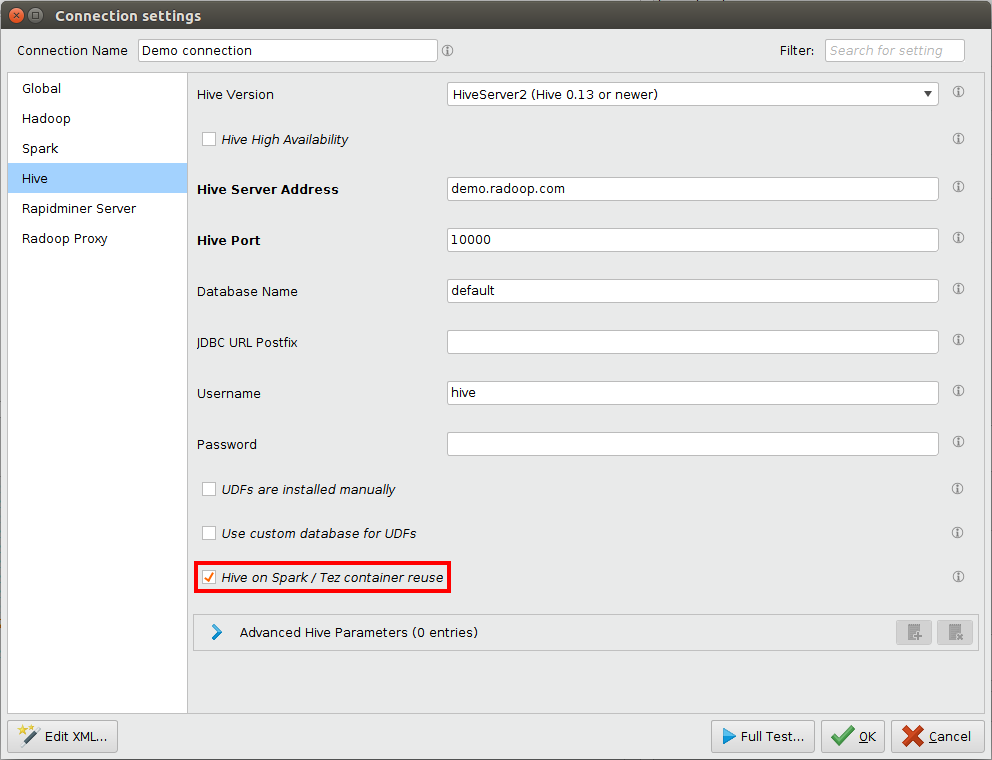
Hive on Spark & Hive on Tez container reuse
Reusing the containers of the Hive execution engine can dramatically speed up Radoop processes, especially if there are lots of Hive-only tasks. It is achieved by keeping a number of Spark / Tez containers (applications) in running state for executing Hive queries. Keep in mind that these containers will use cluster resources even if there are no running processes. Radoop tries to estimate the optimal number of containers by default, but it also can be changed to a fix number in the settings (see below). Idle containers are automatically closed after a timeout.
To use this feature, your cluster must support Hive on Spark or Hive on Tez, and in your connection have to set hive.execution.engine to spark or tez in Advanced Hive Parameters and check Hive on Spark / Tez container reuse checkbox (this is the default value):
A number of global Radoop settings can be used to control the container reuse behaviour. You may want to test different settings to use your cluster optimally, see Radoop Settings for details.
As Hive on Spark / Hive on Tez containers are kept running and reserving cluster resources, you may easily run out of memory/cores on small clusters (e.g. quickstart VMs) if you run other MapReduce, Spark or Tez jobs. To prevent this situation, Radoop automatically stops these containers before starting a MapReduce or Spark job. (Idle containers would have been closed anyway, but this enables closing them before the idle timeout, right when the resources are needed.)
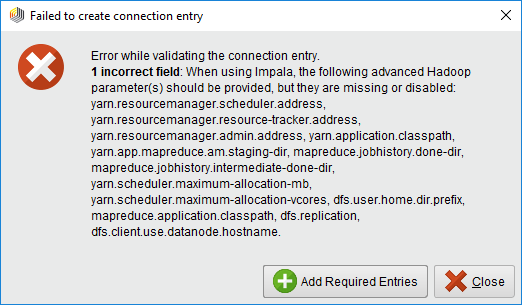
Impala connections
If your are configuring an Impala connection some Advanced Hadoop Parameters need to be added manually. If you forget to add any of those, a warning message will warn you about the missing ones. The Add Required Entries button adds the keys of these properties to the list, but their values must be set manually according to the cluster configuration.
When upgrading Altair AI Studio or Altair AI Hub, further settings may become mandatory, which could mean that the Impala connections may have to be updated with the new required advanced settings.
Exporting Radoop connections to a repository or project
Once the Radoop connection is ready and tested, it can be exported to a repository or project using the ![]() Export... action on the Manage Radoop Connections... dialog.
Export... action on the Manage Radoop Connections... dialog.
Now the Radoop connection is ready to use. Please follow our Radoop basics guide for more information. To fine-tune exported connections, we recommend using connection overrides.